
【标题】Podracer architectures for scalable Reinforcement Learning 【作者团队】Matteo Hessel, Manuel Kroiss, Aidan Clark, Iurii Kemaev, John Quan, Thomas Keck, Fabio Viola, Hado van Hasselt 【论文链接】https://arxiv.org/pdf/2104.06272.pdf 【发表时间】2021.4.13 【推荐理由】本文提出了Podracer架构并已经在JAX中实现,其将该架构统称为为支持TPU Pods上可扩展RL研究而构建的研究平台,并且描述两个有效使用TPU进行大规模强化学习研究的架构(Anakin和Sebulba),分别用于训练在线代理和分解的actor-learner代理。其在可扩展性、易于实施和维护之间找到了平衡点。 研究结果表明,该框架可以提供卓越的性能,并且其训练成本通常比训练缺乏并行性或TPU加速的较小规模代理的成本更小。
要支持最先进的AI研究,需要在快速原型制作,易用性和快速迭代之间取得平衡,并能够以传统上与生产系统相关的规模部署实验.TensorFlow,PyTorch和JAX等深度学习框架允许用户透明地使用加速器(例如TPU和GPU)来减轻现代深度学习系统中,减轻训练和推理的计算密集部分。使用这些框架进行深度学习的流行训练管道通常侧重于(无)监督学习。如何最好地大规模地训练强化学习(RL)代理仍然是一个活跃的研究领域。本文研究者认为TPU特别适合以可扩展,高效和可重现的方式训练RL代理。特别是,其描述两个有效使用TPU进行大规模强化学习研究的框架(Anakin和Sebulba),旨在充分利用TPU Pod上的可用资源(Google数据中心的一种特殊配置,具有通过极低延迟通信通道相互连接的多个TPU设备)。
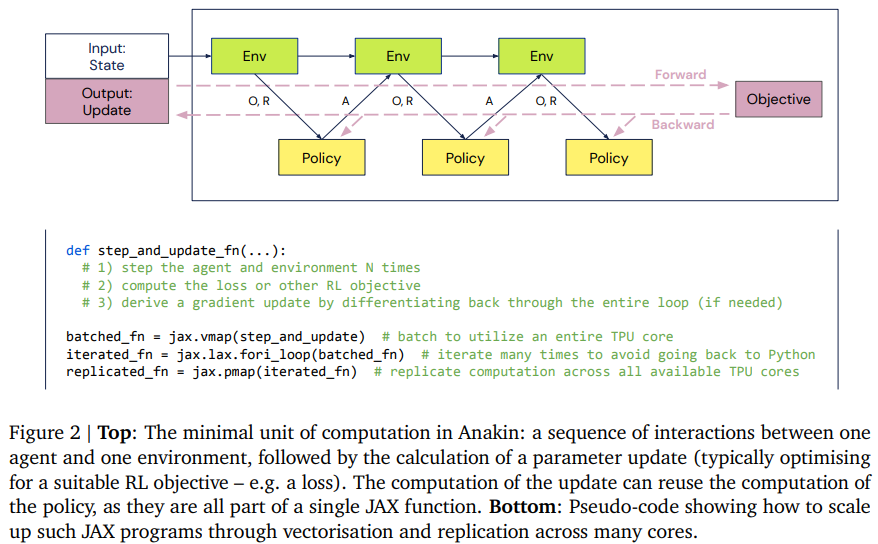
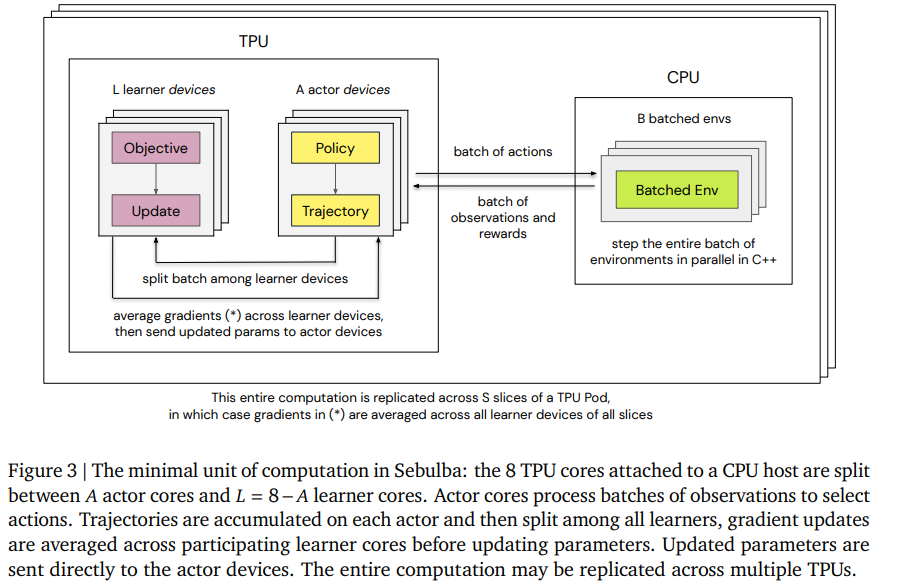
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢