
标题:康奈尔,英伟达|GANcraft:Minecraft Worlds的无监督3D神经渲染
简介:我们展示了GANcraft,一种无监督的神经渲染生成大型3D逼真的图像的框架阻止诸如在Minecraft中创建的世界。我们的方法将语义块世界作为输入,其中每个块都是分配了一个语义标签,例如泥土,草或水。我们将世界表示为连续的体积函数,并且训练我们的模型以为用户控制的相机渲染与视图一致的逼真的图像。在没有配对的情况下为区块世界提供真实的真实图像,我们设计了一个基于伪地面真相和对抗训练的训练技巧。这与先前的用于视图合成的神经渲染工作相反,后者需要地面真实性
图像以估计场景的几何形状和与视图有关的外观。除了摄像机的轨迹,GANcraft还可以用户控制场景语义和输出样式。与强基线比较的实验结果表明GANcraft在逼真的3D块世界合成这一新任务上的有效性。

背后技术原理
原理概述
GANcraft中神经渲染的使用保证了视图的一致性,而创新的模型架构和训练方案实现了空前的真实感。
具体而言,研究人员结合了3D体积渲染器和2D图像空间渲染器,使用Hybird体素条件神经渲染方法。
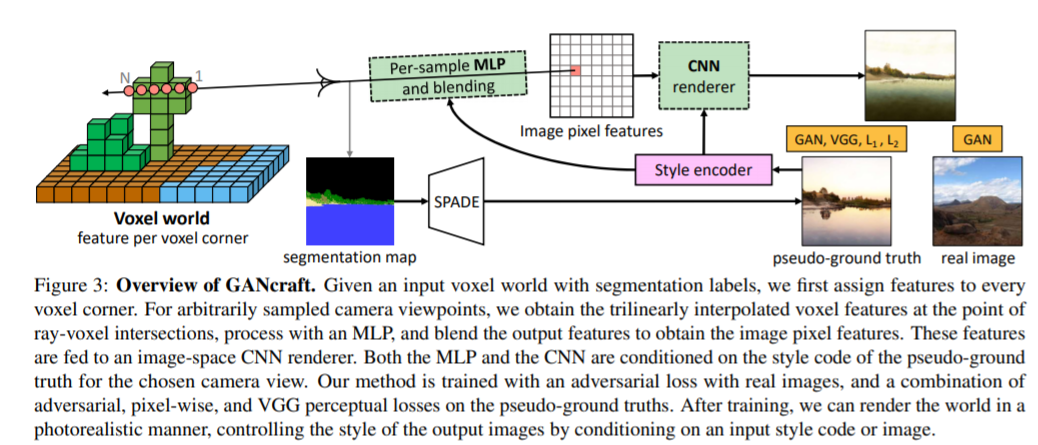
首先,定义一个以体素(即体积元素)为边界的神经辐射场,并且为块的每个角,分配一个可学习的特征向量;
再使用三线性插值法,在体素内的任意位置定义位置代码,把世界表示为一个连续的体积函数;并且每个块都被分配了一个语义标签,如泥土、草地或水。
然后,使用MLP隐式定义辐射场,将位置代码、语义标签和共享的样式代码作为输入,并生成点特征(类似于辐射)及其体积密度。
最后给定相机参数,通过渲染辐射场获得2D特征图,再利用CNN转换为图像。
虽然能够建立体素条件神经渲染模型,但是没有图像能用作ground truth,为此,研究人员采用了对抗训练方式。
但是「我的世界」不同于真实世界,其街区通常具有完全不同的标签分布,比如:场景完全被雪或水覆盖,或是多个生物群落出现在一个区域。
在随机采样时,使用互联网照片进行对抗训练,会生成脱离实际的结果。
因此研究人员生成Pseudo-ground truth,用来进行训练。
使用预训练的SPADE模型,通过2D语义分割蒙版,获得具有相同语义的Pseudo-ground truth图像。
这不仅减少了标签和图像分配的不匹配,而且还能用更强的损失,来进行更快、更稳定的训练。生成效果得到了显著改善:
此外,GANcraft还允许用户控制场景语义和输出风格:
其介绍页中提到:它将每个Minecraft玩家变成了3D艺术家!
代码:https://nvlabs.github.io/GANcraft/
论文下载:https://arxiv.org/pdf/2104.07659.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢