
Transfer Reinforcement Learning Across Homotopy Classes
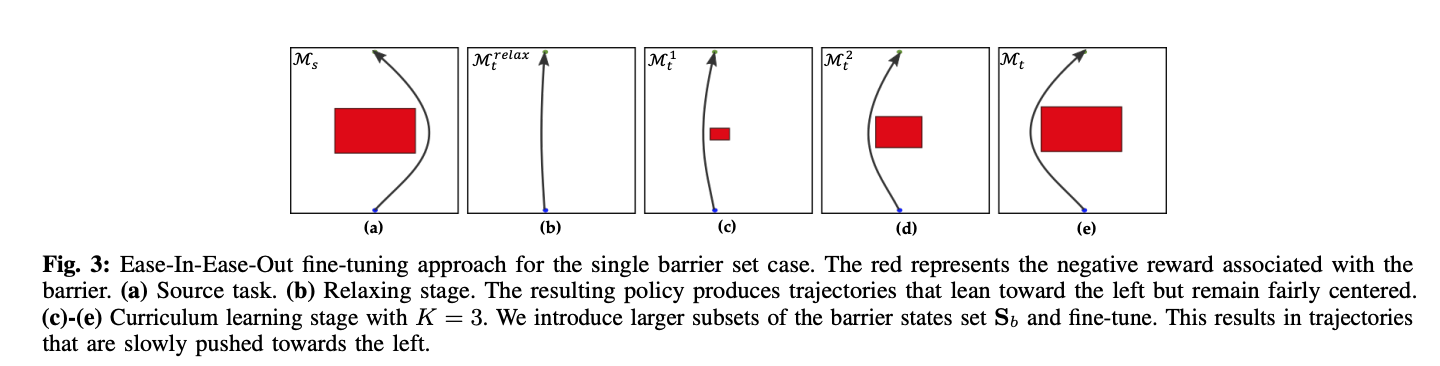
机器人能够将其学到的在数据稀缺的情况下,将知识应用到新的任务中,是一个机器人成功学习的根本挑战。虽然在监督学习的背景下,微调已经作为一种简单而有效的转移方法。不过在强化学习的背景下并没有很好地探索。在这项工作中,我们研究了转移强化学习中的微调问题,当任务的参数化是由它们的奖励函数决定的,这些函数是事先已知。我们推测,微调会极大可能表现不佳,当源和目标轨迹来自于不同类。我们证明,与同构类内的微调相比,跨同构类的策略参数微调需要与环境进行更多的交互,而且在某些情况下是不可能的。我们提出了一种新型的微调算法Ease-In-Ease-Out微调法,该算法由放松阶段和课程学习阶段组成,以实现跨同构类的转移学习。最后,我们在几个机器人启发的模拟环境上对我们的方法进行了评估,并实证了Ease-In-Ease-Out微调方法与现有的基线相比,可以成功地以一种样本高效的方式进行微调。
下面是Ease-In-Ease Out微调的具体演示图及机器人实验。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢