标题:北大,阿里|Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese
Pre-trained Language Models(Lattice-BERT:利用中文的多粒度表示预训练语言模型)
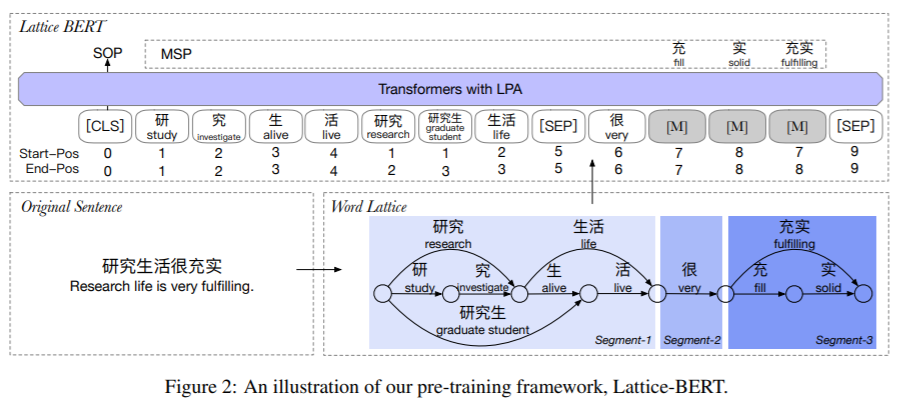
https://arxiv.org/pdf/2104.07204.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

标题:北大,阿里|Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese
Pre-trained Language Models(Lattice-BERT:利用中文的多粒度表示预训练语言模型)
https://arxiv.org/pdf/2104.07204.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢