
【论文标题】Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
【作者团队】A Prakash, K Chitta, A Geiger
【机构】Max Planck Institute for Intelligent Systems
【发表时间】2021/4/19
【论文链接】https://arxiv.org/pdf/2104.09224.pdf
【推荐理由】
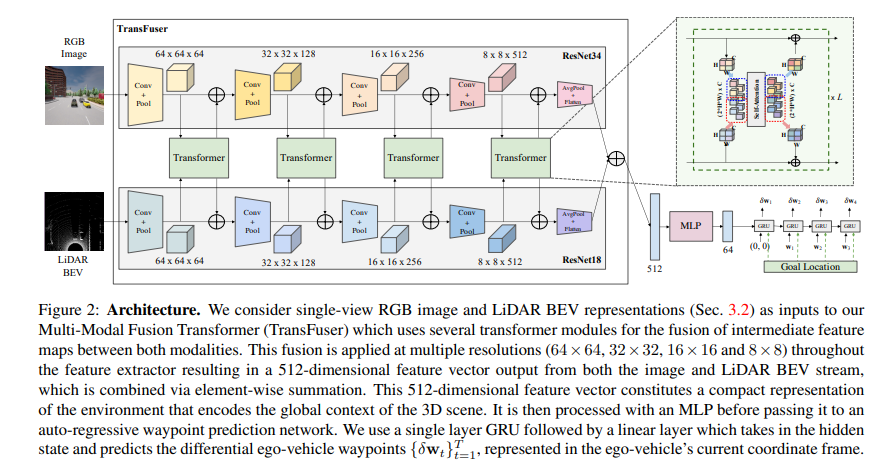
本文来自德国马克斯•普朗克研究所,发表于CVPR 2021。文章面向自动驾驶提出了一种新颖的多模态融合Transformer,以利用注意力整合图像和LiDAR表示。
对无人驾驶来说,应该如何整合来自互补性传感器的表征?基于几何的传感器融合在感知任务中显示出巨大的前景,如目标检测和运动预测。然而,对于实际的驾驶任务,三维场景的全局上下文是关键,例如,交通灯状态的变化,会影响到在几何上远离该交通灯的车辆的行为。因此,仅靠几何学可能不足以有效地融合端到端驾驶模型中的表示。本文证明了基于现有传感器融合方法的模仿学习策略,在高密度的动态智能体和复杂场景中表现不佳,无法处理城市驾驶中的对抗性场景,这些场景需要全局性的推理,例如在不受控制的十字路口,处理从多个方向来的交通。提出了TransFuser,一种新的多模态融合Transformer,用注意力来整合图像和LiDAR的表示,捕捉全局的三维场景上下文,并专注于动态智能体和交通灯。利用CARLA城市驾驶模拟器,在涉及复杂场景的城市环境中实验验证了该方法的有效性,实现了最先进的驾驶性能,与基于几何的融合相比,减少了76%的碰撞。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢