
标题】Reinforcement Learning with a Disentangled Universal Value Function for Item Recommendation
【作者团队】Kai Wang, Zhene Zou, Qilin Deng, Runze Wu, Jianrong Tao, Changjie Fan, Liang Chen, Peng Cui
【研究团队】伏羲AI Lab & 中山大学& 清华大学
【论文链接】https://arxiv.org/pdf/2104.02981.pdf
【发表时间】2021.4.11
【推荐理由】本文提出了新颖的强化学习框架-GoalRec,其目标是解决由于状态/动作空间大,高变异性环境和不确定的奖励设置而引起强化学习(RL)应用于推荐系统(RS)的挑战。该框架可以归纳出推荐者可能具有的各种目标,并将环境演变和奖励分离开来;并可以预测环境动态和子信息(编码在度量中)的模型,以将不同度量编码为推荐者可能具有的各种目标的奖励方式解耦。研究结果表明了该方法的优越性。
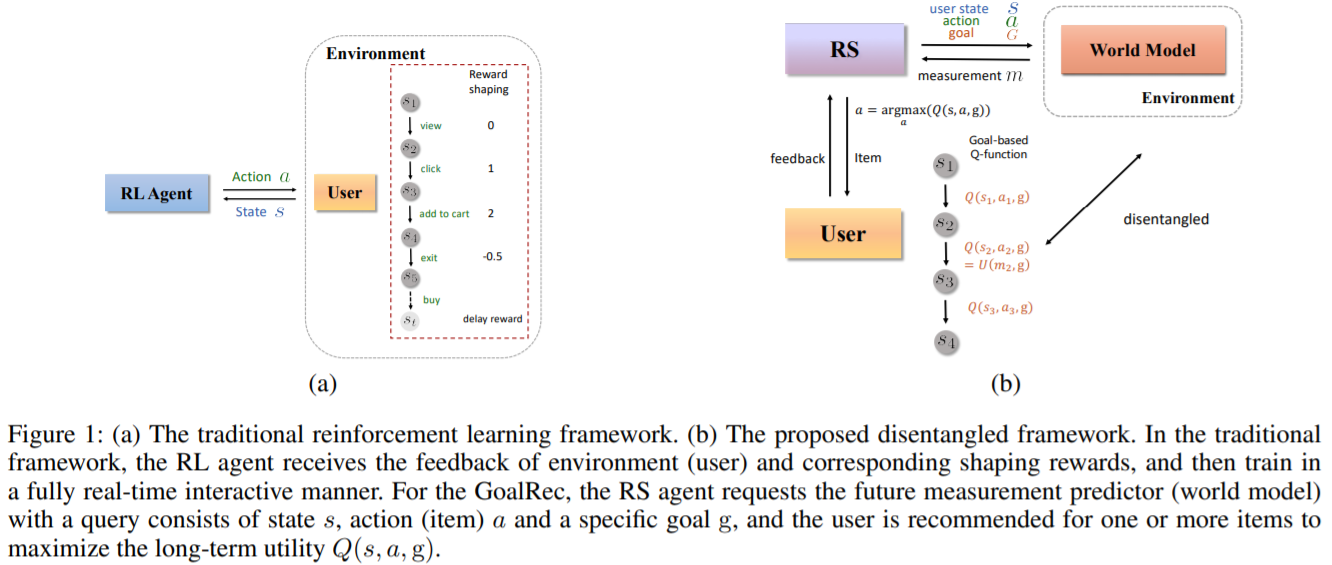
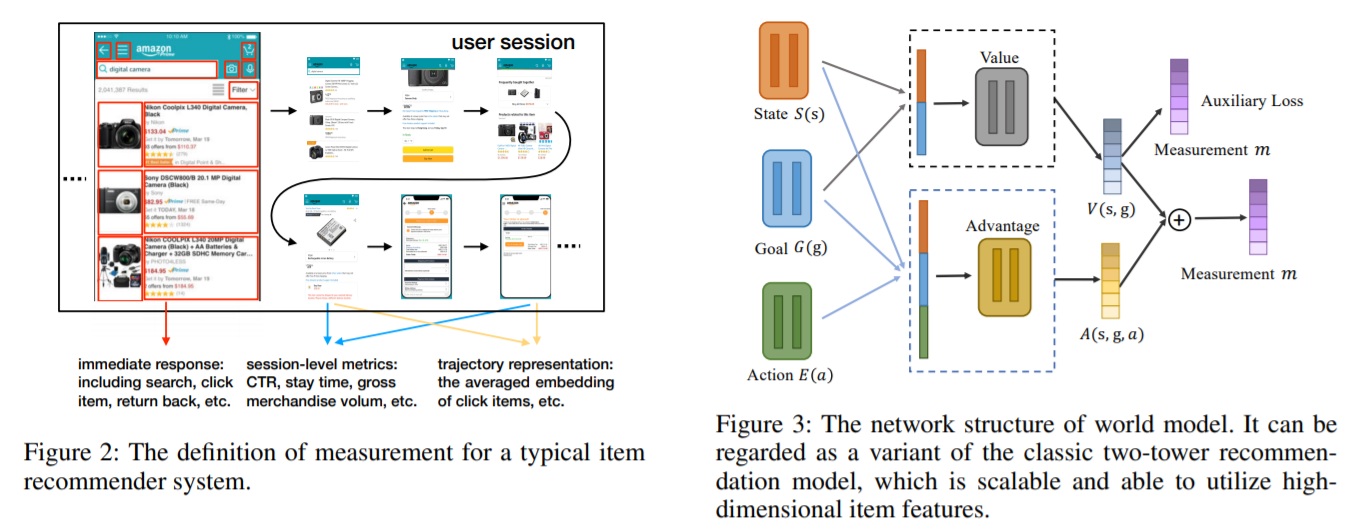
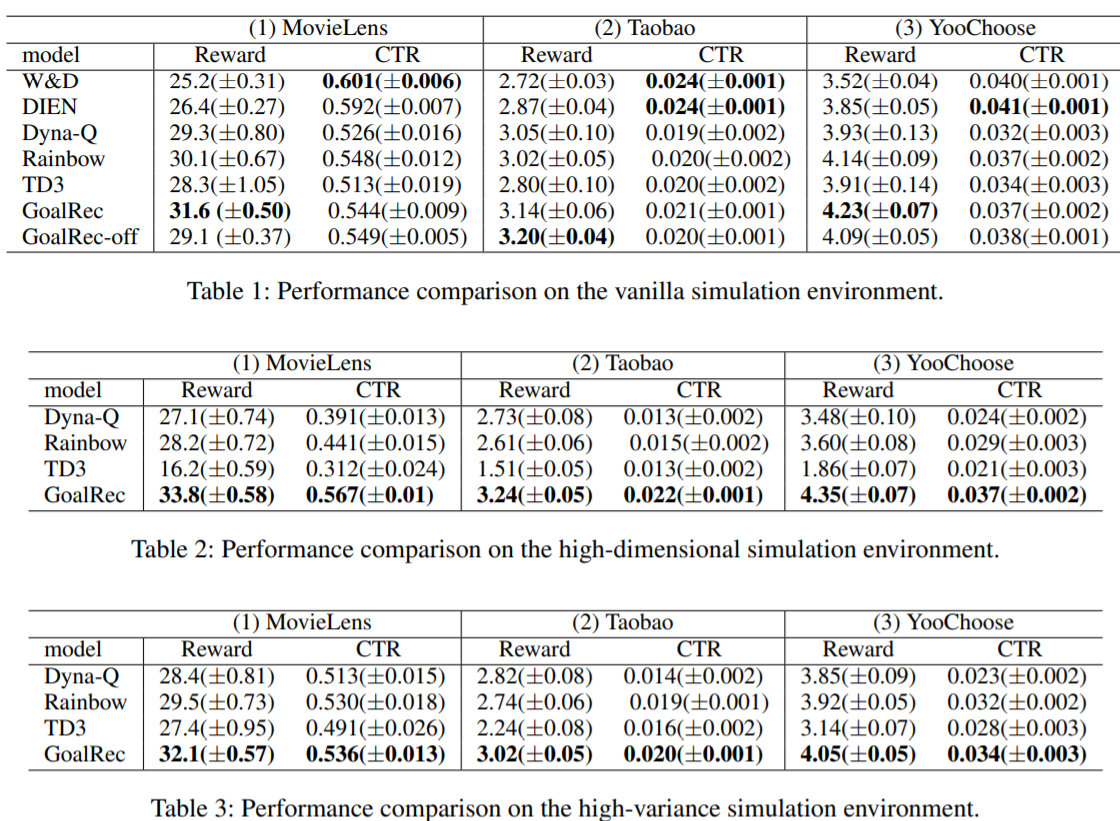
近年来,将强化学习(RL)应用于推荐系统(RS)引起了极大的兴趣和挑战。本文总结了基于RL的大规模推荐系统的三个主要实际挑战:大规模的状态和动作空间,高变异性环境以及推荐中的非特定奖励设置。所有这些问题在现有文献中仍未得到充分探讨,使得RL的应用具有挑战性。本文开发了一个基于模型的强化学习框架,称为GoalRec。受到世界模型(基于模型),价值函数估计(无模型)和基于目标的RL观念的启发,提出了一种新颖的用于商品推荐的解耦通用价值函数。它可以归纳出推荐者可能具有的各种目标,并将环境演变和奖励分离开来。作为价值函数的一部分,从稀疏和高方差的奖励信号中分离出来,训练一个大容量的奖励无关的world模型,以在特定目标下模拟复杂的动态环境。基于预测的动态环境,解耦的通用值函数与用户的未来轨迹相关,而不是与单一状态和标量奖励相关。在一系列模拟和实际应用中,本文证明了GoalRec在上述三个实际挑战方面优于以前的方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢