
论文标题:So-ViT: Mind Visual Tokens for Vision Transformer
论文链接:https://arxiv.org/abs/2104.10935
代码链接:https://github.com/jiangtaoxie/So-ViT
作者单位:大连理工大学 & 天津大学 & 旷视科技
本文提出一种二阶视觉Transformer新网络,表现SOTA!性能优于T2T-ViT、RepVGG等网络,代码刚刚开源!
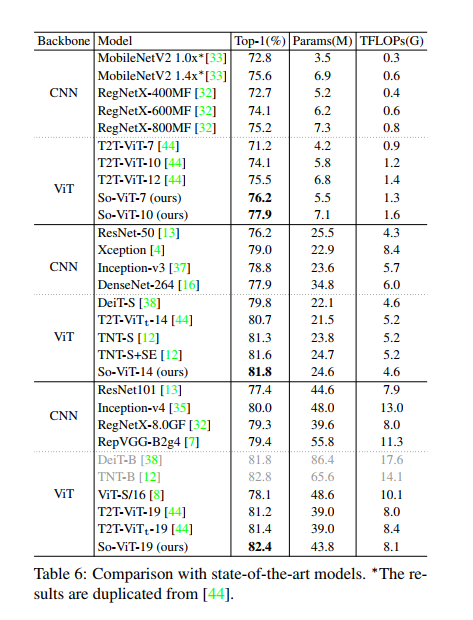
最近,视觉Transformer(ViT)体系结构(其中的骨干网完全由自注意力机制组成)在视觉分类中已经取得了非常有希望的性能。但是,原始ViT的高性能在很大程度上取决于使用超大规模数据集进行的预训练,如果从头开始训练,它在ImageNet-1K上的性能将大大落后。本文通过仔细考虑视觉tokens的作用,努力解决这个问题。首先,对于分类head,现有的ViT仅利class token,而完全忽略了高级visual token固有的丰富语义信息。因此,我们提出了一种新的分类范式,其中视觉标记的二阶交叉协方差池与class token结合在一起以进行最终分类。同时,提出了一种快速的奇异值功率归一化方法,以改善二阶合并。其次,原始的ViT采用固定大小图像patches的naive embedding,缺乏对平移等方差和局部性进行建模的能力。为缓解此问题,我们开发了一种基于现成卷积的轻量级分层模块,用于visual token embedding。我们在ImageNet-1K上对提出的架构(我们称为So-ViT)进行了全面评估。结果表明,我们的模型经过从头训练后,性能优于竞争的ViT变体,并且与最新的CNN模型相当或更好。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢