【论文标题】Distilling Audio-Visual Knowledge by Compositional Contrastive Learning
【作者团队】Yanbei Chen, Yongqin Xian, A. Sophia Koepke, Ying Shan, Zeynep Akata
【发表时间】2021/04/22
【机构】图宾根大学、马普所、腾讯
【论文链接】https://arxiv.org/pdf/2104.10955.pdf
【代码链接】https://github.com/yanbeic/CCL
【推荐理由】
本文出自德国图宾根大学、马普所、腾讯联合实验室,目前已被 CVPR 2021 接收。作者提出了一种跨异构模态知识迁移框架,通过组合对比学习将不同模态表征组合在一起,性能显著优于各种现有的知识蒸馏方法。
与利用单一模态数据学习相比,拥有多模态线索(如视觉和音频)能够让我们更快地完成一些认知任务。在本文,作者提出跨异构模态迁移知识,即使这些数据模态可能并没有语义相关性。作者并非直接对齐不同模态的表征,而是跨模态组合音频、图像和视频表征,以揭示更丰富的多模态知识。本文的核心思想是学习一种能够缩小跨模态语义差距并捕获与任务相关语义的组合嵌入,从而通过组合对比学习将不同模态的表征组合在一起。
作者在 UCF101、ActivityNet 和 VGGSound 三个视频数据集上建立了一个新的、全面的多模态蒸馏对比基准。此外,作者还证明了本文提出的模型在迁移音频-视觉知识以改善视频表征学习的方面显著优于现有的各种知识蒸馏方法。
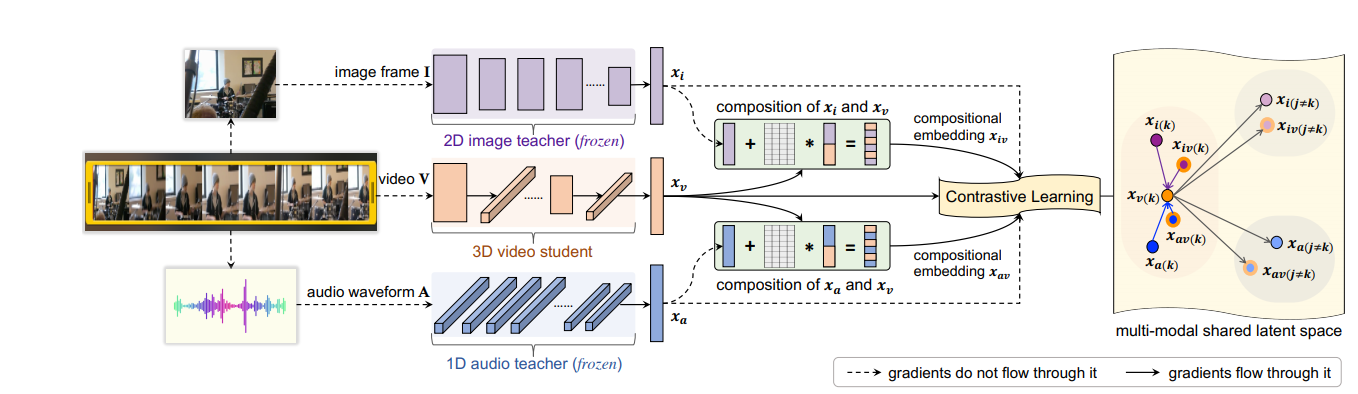
图 1:模型架构示意图
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢