
简介:ACM SIGIR是信息检索和数据挖掘的顶级会议,享有很高的学术声誉。近日,第44届ACM SIGIR公布录用结果,华为诺亚方舟实验室推荐与搜索的3篇长文被接收(另有3篇短文被接收)。本文将概要介绍这3项长文研究成果,欢迎大家关注诺亚方舟实验室的公众号,后续我们将带来相关研究成果的详细介绍。
1. A Graph-Enhanced Click Model for Web Search
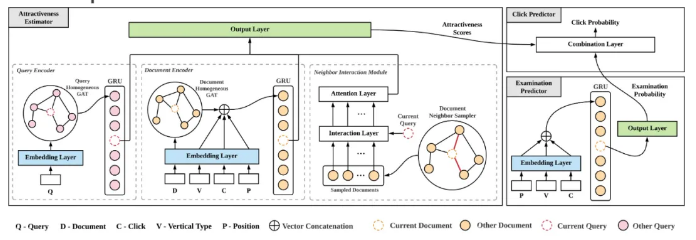
用户点击模型能够从用户的隐式交互反馈中学习和建模用户的行为模式,理解用户行为。大多数传统的点击模型都基于概率图模型(PGM)框架,该框架需要手动设置变量间的依赖关系,可能过度简化了用户行为。近期提出的基于神经网络的方法能够通过增强表达能力和允许灵活依赖来提高对用户行为的预测精度。然而,现有的此类方法仍然面临着数据稀疏和冷启动问题。在本文中,我们提出了一种新颖的使用图结构的点击模型 (GraphCM)。首先,我们将每个查询或文档视为一个图结点,并创新地提出了分别对查询和文档构造同质图的构图方式,充分利用会话内和会话间信息来解决稀疏性和冷启动问题。其次,根据用户检验假设 (examination hypothesis),我们分别设计了吸引力估计器和检验概率预测器,用以分别输出吸引力分数和检测概率。其中,我们使用了图神经网络和邻域交互技术从构造好的图结构中提取有效的辅助信息。最后,我们将模型预测出的吸引力分数和检测概率值组合起来用于预测用户点击概率。本文在三个真实场景的数据集上进行了充分的实验,实验表明GraphCM不仅预测精度优于现有模型,同时在解决数据稀疏和冷启动问题方面也取得了更优的性能。【诺亚方舟推荐与搜索团队与上海交通大学俞勇老师/张伟楠老师/李帅老师的联合工作】
2. ScaleFreeCTR: MixCache-based Distributed Training System for CTR Models with Huge Embedding Table
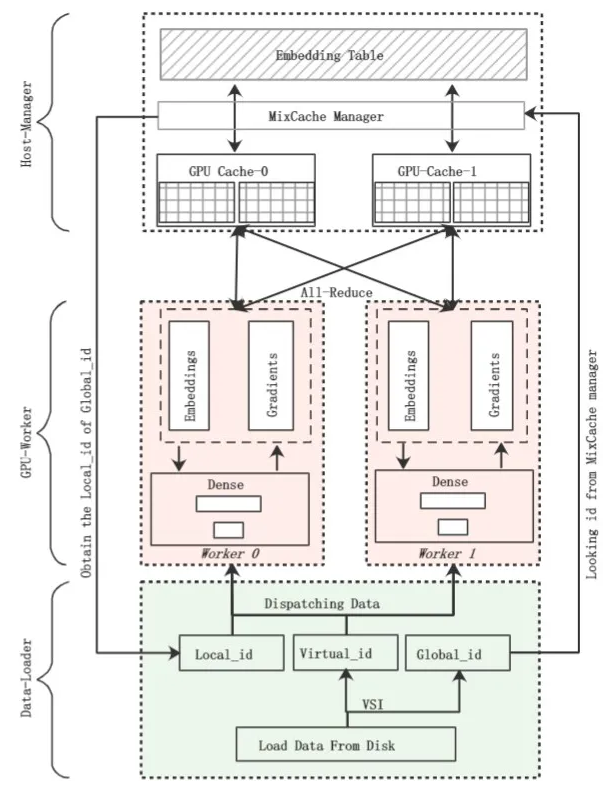
深度学习模型具备优越的特征表示能力,因此,越来越多公司的推荐系统部署了深度推荐模型,如深度点击率预测模型(Click-Through-Rate Prediction)。众所周知,在深度学习时代,数据和模型同等重要,因此需要基于海量数据训练模型以取得更好的预测效果。此外,在推荐搜索场景,由于模型时效性对推荐效果影响很大,故模型训练速度也十分重要。因此,如何基于海量数据高效完成模型的训练对于推荐系统十分关键。
与机器视觉、自然语言处理任务不同,推荐数据高维稀疏:高维指推荐数据包含大量的id类特征,特征维度可达亿级甚至百亿级别;稀疏指每一条样本只会有很小一部分的id类特征出现。为更好的训练模型,大多数深度推荐模型都会使用Embedding层将高维稀疏的数据转换为低维稠密向量。Embedding层参数和特征维度相关,很容易达到百GB甚至TB,单个GPU显存无法容纳全部Embedding参数。因此,仅基于数据并行难以通过分布式加速训练,而现有工作都采用模型并行,具体来说采用CPU内存维护Embedding参数,利用GPU进行前向和反向计算。这些工作在Host和GPU之间频繁pull & push数据、基于CPU更新和同步参数,存在性能瓶颈。因此,我们提出了ScaleFreeCTR,一个针对超大规模EmbeddingCTR模型的基于混合缓存的分布式训练系统。在ScaleFreeCTR中,为减少GPU-CPU之间由于数据传输造成的延迟,我们提出了Virtual Sparse Id操作和Mix-Cache机制。实验表明,相比于对比基线,ScaleFreeCTR可以拥有更高的训练效率。目前,ScaleFreeCTR已部署于华为浏览器信息流和应用市场,带来离线训练效率和测试指标的显著提升。【诺亚方舟实验室推荐与搜索团队与AI系统工程团队的联合工作】
3. Hierarchical Cross-Modal Graph Consistency Learning for Video-Text Retrieval
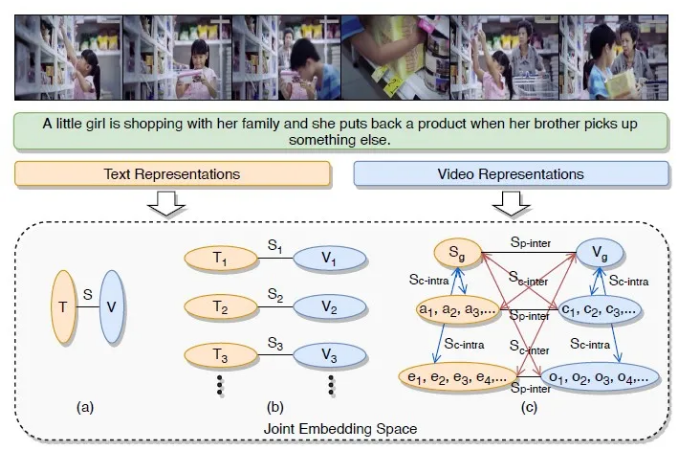
由于互联网上视频内容的普及,视频和文本之间的信息检索引起了研究者的广泛兴趣,这是一项具有挑战性的跨模态检索任务。目前常见的解决方案是学习一个联合嵌入空间来测量跨模态相似性。然而,现有的许多方法大都只关注了文本信息、视频信息或跨模态匹配方法这三者中的部分,而一个好的视频文本检索系统应该兼顾这三点,充分挖掘这两种模态的语义信息,并考虑综合层次的匹配。因此,本文针对视频文本检索任务,提出了一种层次化的跨模态图一致性学习网络(Hierarchical Cross-Modal Graph Consistency Learning Network,HCGC),该方法考虑了视频图与文本图不同层级间的多重一致性。具体来说,我们首先构建了视频的层级图表示,其中包括从全局到局部的三个层次:视频整体、片段和对象。同样,根据句子、动作和实体之间的语义关系,我们构建相应的文本层级图。然后,为了学习视频和文本图之间更全面的匹配,我们设计了三种图的一致性学习:图内交叉一致性、图间交叉一致性和图间平行一致性。在不同视频文本检索数据集上的大量实验结果证明了我们的方法在文本到视频和视频到文本检索上的有效性。【诺亚方舟推荐与搜索团队与浙江大学赵洲老师的联合工作】
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢