标题:脸书、伯克利|Multiscale Vision Transformers(多尺度视觉变换器)
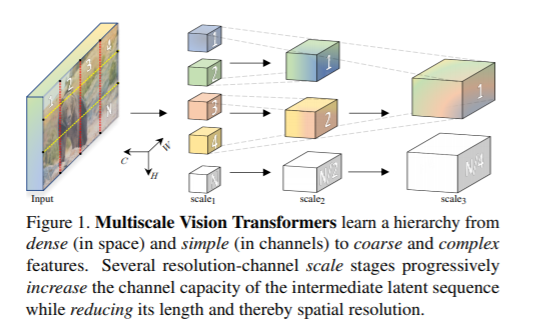
简介:我们展示了多尺度视觉变换器(MViT)结合开创性的想法进行视频和图像识别变换器模型的多尺度特征层次结构。多尺度变换器具有多种通道分辨率规模尺度,从输入分辨率和小渠道维度,各个阶段会逐步扩展通道容量,同时降低空间分辨率。这创建具有早期图层的多尺度要素金字塔,这些早期图层在高空间分辨率下运行以对简单模型进行低层的视觉信息建模,以及在空间上更深的层次粗糙但复杂的高维特征。我们先评估此基本架构,然后再对在各种视频识别任务中,视觉信号具有密集的性质,其性能优于依靠大规模外部预训练和视觉识别的并发视觉变换器,但在计算和参数上要多5到10倍的成本。进一步,我们消除时间维度并应用我们的模型用于图像分类,胜过先前的工作在视觉变换器上,MViT在ImageNet上取得了84.8%的Top1准确率。
代码:https://github.com/facebookresearch/SlowFast
论文地址:https://arxiv.org/pdf/2104.11227v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢