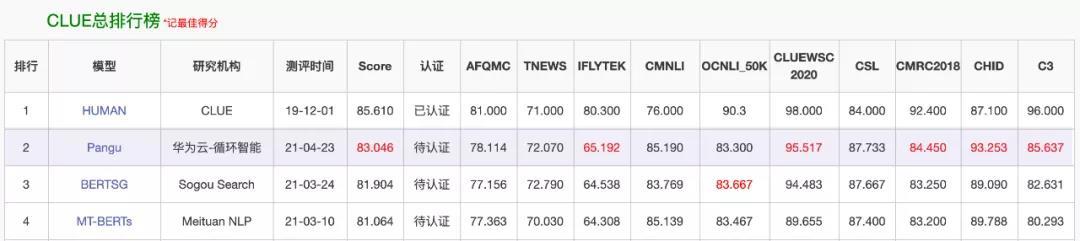
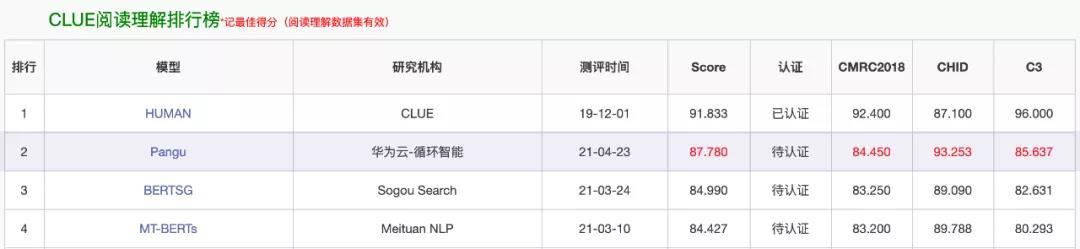
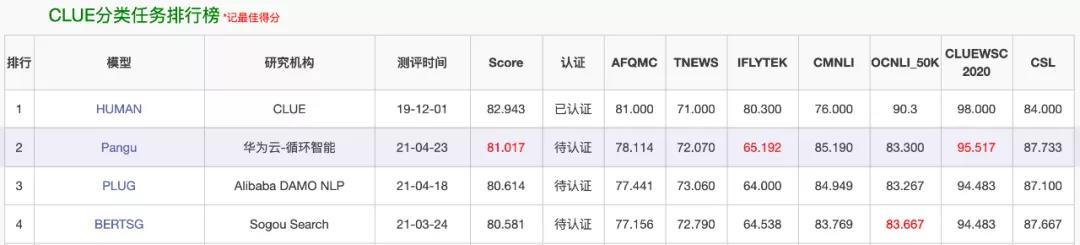
这次刷榜的,是一个叫「盘古」的 NLP 模型。在最近的 CLUE 榜单上,「盘古」在总榜、阅读理解排行榜和分类任务排行榜上都位列第一,总榜得分比第二名高出一个百分点。
更多详情可以戳原文。
来源:机器之心
内容中包含的图片若涉及版权问题,请及时与我们联系删除

这次刷榜的,是一个叫「盘古」的 NLP 模型。在最近的 CLUE 榜单上,「盘古」在总榜、阅读理解排行榜和分类任务排行榜上都位列第一,总榜得分比第二名高出一个百分点。
更多详情可以戳原文。
来源:机器之心
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢