
【论文标题】When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holding
【作者团队】Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, Daniel E. Ho
【发表时间】2021/04/18
【机 构】斯坦福大学,美国
【论文链接】https://arxiv.org/pdf/2104.08671v1.pdf
【代码链接】https://github.com/reglab/casehold
【推荐理由】法律领域的领域预训练及相应benchmark数据
虽然自监督学习在自然语言处理方面取得了快速的进展,但研究人员何时应该进行资源密集型的特定领域预训练(领域预训练)仍不清楚。令人不解的是,尽管法律语言被广泛认为是独特的,但法律领域的预训练却几乎没有产生实质性收益。作者假设这些现有的结果源于这样一个事实,即现有的法律NLP任务太过于简单以至于未能满足领域预训练的条件。为了解决这个问题,本文首先提出了CaseHOLD(关于法律裁决的案例集),这是一个新的数据集,由超过53,000个多选题组成,用于识别所引用案例的相关联裁决。这个数据集为律师提供了一个基本的任务,从NLP的角度来看,它既具有法律意义又很困难(BiLSTM基线的F1为0.4)。第二,本文评估了CaseHOLD和现有法律NLP数据集的性能提升。虽然在一般语料库(谷歌图书和维基百科)上预训练的Transformer架构(BERT)提高了性能,但使用自定义法律词汇的领域预训练(使用比BERT的大的美国所有法院的约350万个裁决的语料库)在CaseHOLD上表现出更可观的性能收益(F1提升7.2%,比BERT提高了12%),并在其他两个法律任务上有一定的性能收益。第三,本文表明,当任务与预训练语料库表现出足够的相似性时,领域预训练可能是有必要的:三项法律任务的性能提高水平与任务的领域特性直接相关。本文的发现向研究人员揭示何时应该进行资源密集型的预训练,并表明基于Transformer的架构也可以学习独特法律语言的embedding。
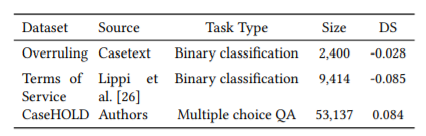
上图为数据概览,本文主要参考3个不同数据集。
- Overruling, 驳回任务是一个二元分类任务,其中正面的例子是驳回的句子,负面的例子是法律中的非驳回的句子。
- Terms of Service, 服务条款任务是一项二元分类任务,其中正面的例子是合同文件中服务条款中潜在的不公平合同条款(条款)。
- CaseHOLD, 是一项由司法裁决中的法律引文衍生出来的多选题回答任务。司法判决中的引证背景是问题的prompt,答案选择是来自于法律裁决中文本之后的引文的持有声明,每个引用文本有五个答案选项,正确的答案是与引用文本相对应的观点声明,四个不正确的答案是其他观点
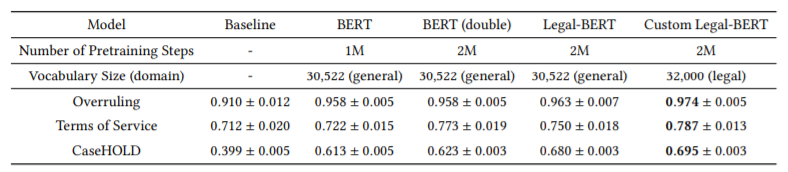
结果概览如上,可以发现Custom Legal-BERT,使用特定的法律领域特定词汇语料库训练的BERT模型表现最好,而且在CaseHOLD上效果提升极其明显。
本文的结果解决了法律NLP中出现的一个难题:如果法律语言是相当独特的,为什么我们看到法律领域的预训练只有边际收益?文章的证据表明,这些结果可以被解释为现有的法律NLP基准任务要么太容易,要么与领域不匹配。我们的论文显示,在任何法律任务中,预训练的收益是最大的。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢