【论文标题】Continual Learning for Text Classification with Information Disentanglement Based Regularization
【论文链接】https://arxiv.org/abs/2104.05489
【代码链接】https://github.com/GT-SALT/IDBR
【作者团队】Yufan Huang, Yanzhe Zhang, Jiaao Chen, Xuezhi Wang, Diyi Yang
【发表时间】2021.4.12
【推荐理由】论文收录于NAACL-2021会议,研究人员为文本分类的持续学习提出了一种基于信息解耦的正则化方法,实验结果表明论文方法优于当前最先进的基准模型。
持续学习已经变得越来越重要,因为它使NLP模型能够随着时间的推移不断学习、获得新知识。以前的持续学习方法主要是为了保留以前任务中的知识,而不太重视如何将模型推广到新的任务中。在这篇论文中,首先将文本隐藏空间分解为对所有任务通用的表示和对每个单独任务特定的表示,并进一步对这些表示进行不同的正则化,以更好地约束归纳所需的知识。同时,引入了两个简单的辅助任务:下一句话预测和任务ID预测,以学习更好的通用和特定的空间表示。在大规模基准数据集上进行的实验表明,论文的方法在各种序列和长度的连续文本分类任务上优于最先进的基线模型。
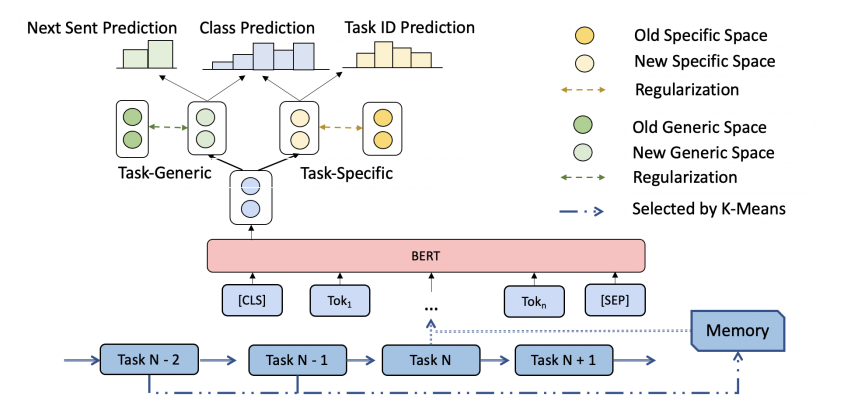
图:模型结构图
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢