
【标题】Independent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
【作者团队】Chengwei Zhang, Shan Jin, Wanli Xue, Xiaofei Xie, Shengyong Chen, Rong Chen
【研究团队】大连海事大学&南洋理工大学&天津理工大学
【论文链接】https://arxiv.org/pdf/2104.10917.pdf
【推荐理由】本文针对交通信号控制领域的全局协作问题,提出了一种考虑交叉口网络关系的部分可观测的弱合作交通模型(PO-WCTM)。并在POWCTM的基础上,提出了一种多智能体协作控制方法CIL-DDQN,用于学习协作控制策略,以优化车辆通过多个交叉口的总吞吐量。在一个模拟和两个真实的交通场景中评估了所提出的方法,实验结果表明了所提出的模型和算法的有效性。
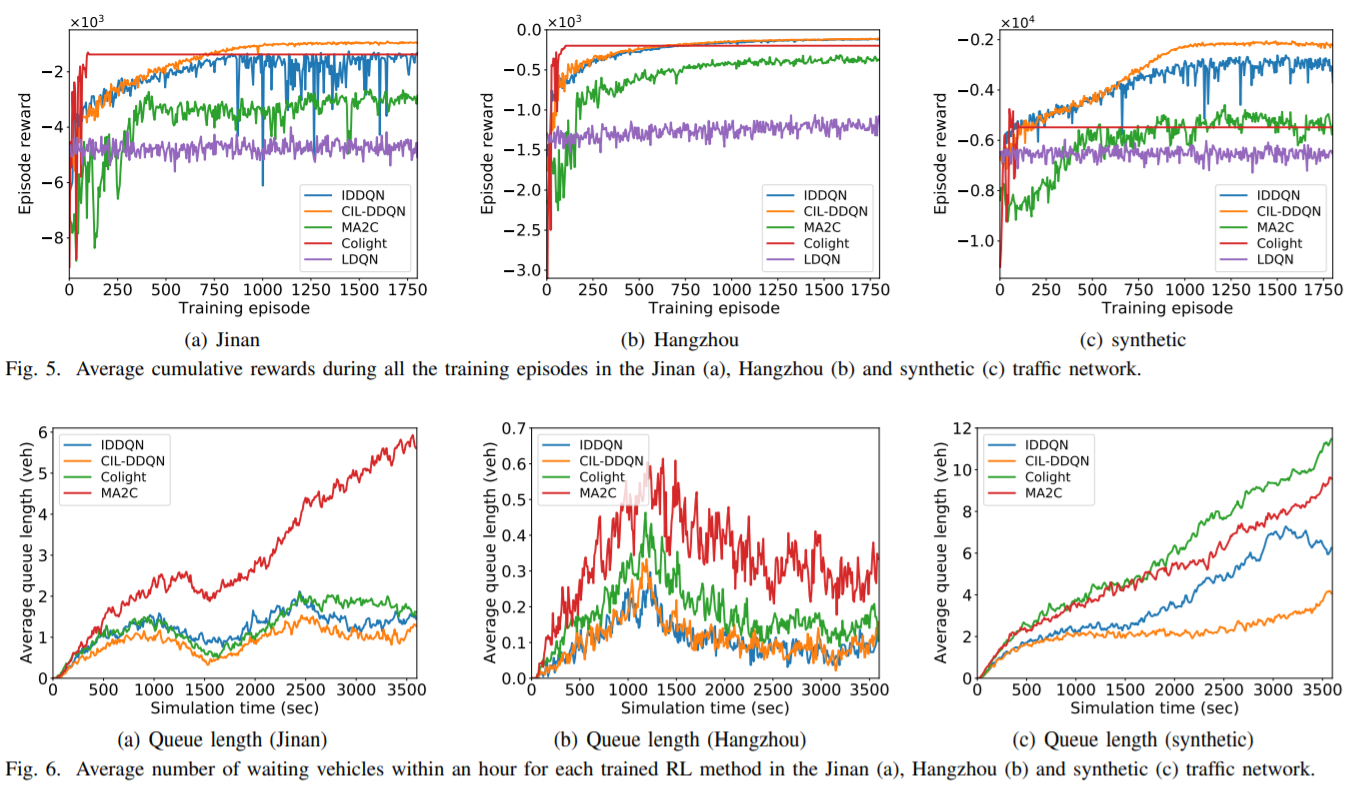
自适应交通信号控制(ATSC)问题可以建模为城市交叉口之间的多智能体合作博弈,交叉口通过合作来优化其共同目标,即城市交通状况。在实际交通场景中,交叉口的规模很大,如何通过同时控制多个交叉口来寻找最优的联合控制策略是一个重大的挑战。近年来,强化学习(RL)在处理顺序决策问题上取得了显著的成功,这促使本文将RL应用于交通控制问题。特别是,独立强化学习(IRL)通常用于解决多智能体任务,其中IRL智能体根据特定规则(如“乐观”或“宽容”原则)独立学习合作策略,并将其他智能体视为环境的一部分。考虑到城市交通环境中交叉口的规模较大,本文采用IRL来解决一个复杂的交通协同控制问题。该问题最大的挑战之一是交叉口的观测信息通常是部分可观测的,这限制了IRL算法的学习性能。为了缓解这一挑战,本文将交通控制问题建模为一个部分可观测的弱合作交通模型(PO-WCTM),以优化一组交叉口的整体交通状况。与传统的IRL任务在完全合作博弈中平均所有代理的收益不同,PO-WCTM中每个交叉口的学习目标是降低合作学习的难度,这也符合交通环境假设。为了确定POWCTM的最优协作策略,本文还提出了一种称为协作重要宽容双DQN(CIL-DDQN)的IRL算法,该算法利用遗忘经验机制和宽容权值训练机制两种机制对Double DQN(DDQN)算法进行了扩展。前一种机制降低了存储在经验应答缓冲区中的经验的重要性,解决了由于其他agent策略改变而导致的经验失败问题。后一种机制增加了高估计的权值经验,并对DDQN神经网络进行了“宽容”训练,提高了协作联合策略选择的概率。实验结果表明,在两个真实交通场景和一个模拟交通场景中,CIL-DDQN在几乎所有的交通控制性能指标上都优于其他方法。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢