
简介:现在的新闻业面临着新闻更新速度过快,用户兴趣变化莫测的挑战,一方面用户被眼花缭乱的信息所淹没,沉浸在“信息茧房”中。另一方面各大巨头都在想尽办法要占领用户的碎片化时间,而实现这一切的关键,都离不开推荐系统。
4月12日的《HelloWorld公开课》,让我们跟着前360高级算法专家熊安斌博士,来看看推荐系统是如何“统治”我们的喜好的。
AC学习
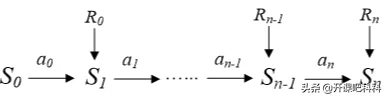
先来回顾下上节课的内容,什么是强化学习?所谓的强化学习,就是在t时刻,Agent的感知环境状态为St;执行动作At,接收到环境的奖赏/惩罚Rt,环境接收到agent的动作At,产生新的状态St+1,释放新的奖赏/惩罚Rt+1。
所以我们可以把强化学习的状态转移流程看作是是一个典型的马尔科夫决策过程(MDP)
强化学习一般分Value-based与Policy-Based两大类,Value-based:基于值的强化学习算法的基本思想是根据当前的状态,计算采取每个动作的价值,然后根据价值贪心的选择动作。
Policy-Based:直接根据状态输出动作或者动作的概率,神经网络输入当前的状态,网络就可以输出我们在这个状态下采取每个动作的概率。而所谓的AC学习中的A就是actor,代表着玩家,C代表Critic,代表评委。我们先来看下这两都是什么意思。
Actor(玩家):为了玩转这个游戏得到尽量高的reward,你需要实现一个函数:输入state,输出action。可以用神经网络来近似这个函数。剩下的任务就是如何训练神经网络,让它的表现更好(得更高的reward)。这个网络就被称为actor。
Critic(评委):为了训练actor,你需要知道actor的表现到底怎么样,根据表现来决定对神经网络参数的调整。这就要用到强化学习中的“Q-value”。但Q-value也是一个未知的函数,所以也可以用神经网络来近似。这个网络被称为critic。”
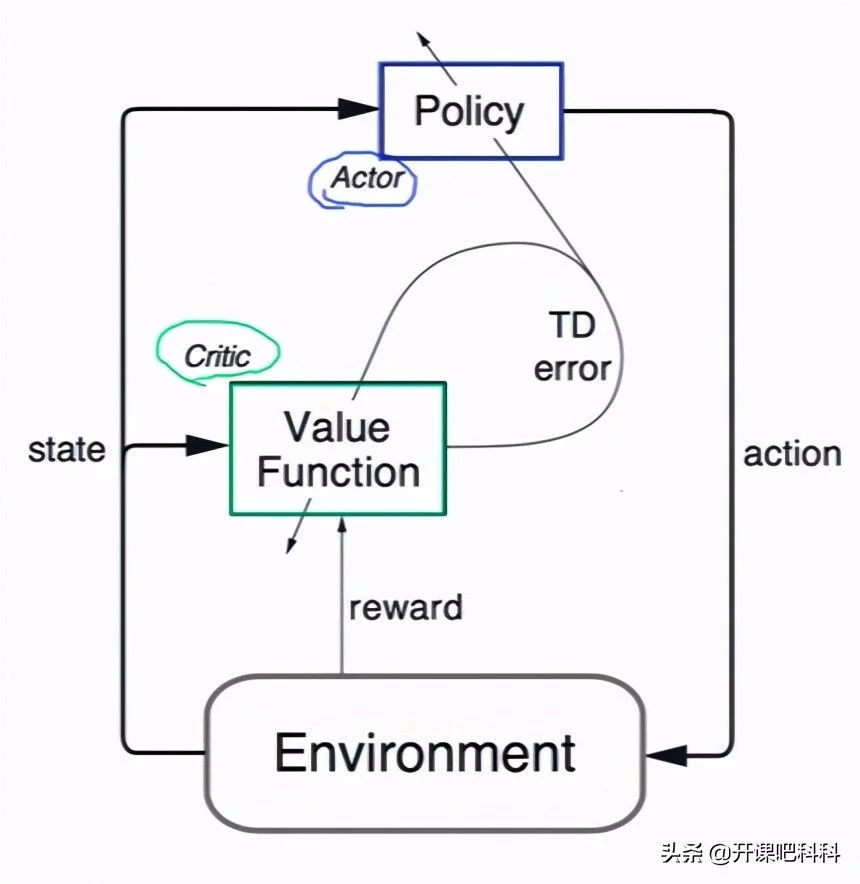
AC学习原理结构图
DDPG算法
我们先来回顾一下上节课所学习的DQN算法,在上节课的学习中同学们应该记得,DQN算法有以下四个缺点
DL需要大量带标签的样本进行监督学习;RL只有reward返回值,而且伴随着噪声,延迟(过了几十毫秒才返回),稀疏(很多State的reward是0)等问题;
DL的样本独立;RL前后state状态相关;
DL目标分布固定;RL的分布一直变化,比如你玩一个游戏,一个关卡和下一个关卡的状态分布是不同的,所以训练好了前一个关卡,下一个关卡又要重新训练;
过往的研究表明,使用非线性网络表示值函数时出现不稳定等问题。
同时,基于上面的问题,我们也给出了解决方案,那就是通过Q-Learning使用reward来构造标签,利用experiencereplay(经验池)的方法来解决相关性及非静态分布问题。
在此基础上,我们可以把DDPG算法看作是采用卷积神经网络作为策略函数μ和Q函数的模拟,即策略网络和Q网络;使用深度学习的方法来训练上述神经网络。
DDPG采用了与DQN类似的双网络结果,Actor和Critic都有target-net和eval-net,但需要注意的是,我们只需要训练动作估计网络和状态估计网络的参数,而动作现实网络和状态现实网络的参数是由前面两个网络每隔一定的时间复制过去的。
Critic网络学习目标函数为图片:
,现实的Q值不再使用贪心算法来选择动作A‘,而是动作现实网络中得到的A'。Critic的状态估计网络的训练还是基于现实的Q值和估计的Q值的平方损失。
但如果只使用单个“Q神经网络”的算法,学习过程很不稳定。因此DDPG分别为策略网络、Q网络各创建两个神经网络拷贝,一个是online网络,一个是target网络
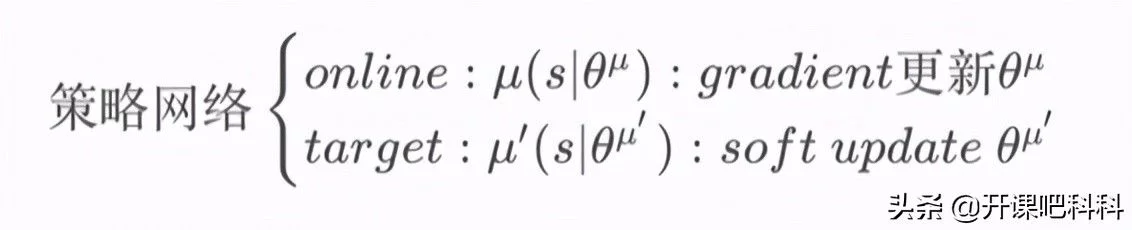
在训练完一个mini-batch的数据后,通过SGA/SGD算法更新online网络的参数,经过softupdate算法更新target网络的参数。
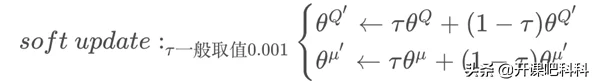
基于强化学习的推荐系统构建
之前我们说过,现在的新闻业面临着三大挑战新闻更新速度快、用户兴趣根据时间变化速度快、寻找相似的物品,可能会降低用户的兴趣。
所以通过使用DeepQ-Learning框架,需要同时考虑现在和未来的reward。将用户的活跃度作为提升推荐效果的指标,这比将用户点击率作为标签所蕴含的信息量更多。将用户的隐含特征表示作为状态,新闻的特征表示作为action,用户点击率以及用户活跃度相结合作为reward。
接下来,我们来看看,如何利用之前学习的DDPG算法来构建推荐系统,如下图所示,State为Agent对Environment的观测,即用户的意图和所处场景。Action代表以List-Wise粒度对推荐列表做调整,考虑长期收益对当前决策的影响。Reward是根据用户反馈给予Agent相应的奖励,为业务目标直接负责。P(s,a)为Agent在当前States下采取Actiona的状态转移概率。

这里我们仔细的看下Reward是如何产生的,之前说过,不能只考虑用户点击率,也要考虑到用户的付费,所以下面的score同时包含了这两项,而r公式在此基础上加入了两个惩罚项。
Penalty1惩罚没有发生任何转化(点击/下单)行为的中间交互页面,从而让模型学习用户意图转化的最短路;Penalty2惩罚没有发生任何转化且用户离开的页面,从而保护用户体验。
以上是利用DDPG算法搭建推荐系统的原理,如果有同学想对强化学习和推荐系统有更深入的了解,同时想了解如何用DQN构建推荐系统,可以点击深度掌握强化学习(下)从Robot到AlphaGo观看公开课的回放视频!
如果有同学想要熊老师授课的PPT文件以及后续HelloWorld公开课信息,可以点击了解更多报名学习哦!

讲师介绍
熊安斌,博士,前奇虎360高级算法专家、技术总监。2015年毕业于中国科学院沈阳自动化研究所模式识别与智能系统专业,研究方向为可穿戴机器人、机器学习。2015年7月加入华为技术有限公司南京研究所,从事大数据平台开发、视频推荐、潜客挖掘、时空洞察等方面的开发工作;2017年7月加入北京奇虎360科技有限公司大数据中心,从事文本分类、广告点击率预测、智慧城市等方面的研发工作。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢