【论文标题】Does BERT Pretrained on Clinical Notes Reveal Sensitive Data?
【作者团队】Eric Lehman, Sarthak Jain, Karl Pichotta, Yoav Goldberg, Byron C. Wallace
【发表时间】2021/04/15
【机 构】MIT CSAIL & 东北大学 & 紀念斯隆-凱特琳癌症中心 & 艾伦人工智能研究院,美国
【论文链接】https://arxiv.org/pdf/2104.07762.pdf
【代码链接】https://github.com/elehman16/exposing_patient_data_release
【推荐理由】预训练&医疗健康中的安全问题
在电子健康记录(EHR)的临床记录上完成预训练的大型transformer在预测临床任务的性能很优秀。训练这种模型的成本以及数据获取权限的需要,加上它们的效用促使了参数共享,即相应预训练的模型的发布,如ClinicalBERT。虽然大多数的工作都使用了未识别的 EHR,但许多研究人员可以获得大量敏感的、未识别的 EHR,他们可以用这些 EHR 训练 BERT 模型或类似预训练模型。如果他们这样做,公布这样一个模型的权重是否安全?在这项工作中,作者设计了一系列方法,旨在从训练好的BERT中恢复个人健康信息(PHI)。具体来说,作者试图从模型中恢复病人的姓名和与之相关的病情,最终发现,简单的探测方法无法从在MIMIC-III EHR语料库中训练的BERT中有意义地提取敏感信息,然而更复杂的 "攻击 "可能会成功做到这一点。
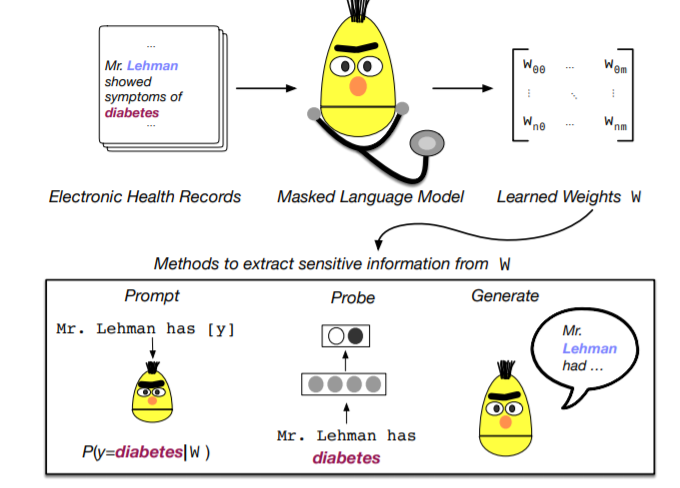
上图为这项工作的概述。本文探讨了从电子健康记录(EHR)数据中通过估计的BERT模型权重中提取敏感信息的初步策略。本文涉及到了数个任务,包括基于MLM的填空模板探索,患者姓名和症状隐变量相似度,患者姓名的重构,患者姓名信息的泄露等等。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢