【论文标题】A General Offline Reinforcement Learning Framework for Interactive Recommendation
【研究团队】西湖大学
【论文链接】https://www.aaai.org/AAAI21Papers/AAAI-9385.XiaoT.pdf
【发表时间】AAAI-2021
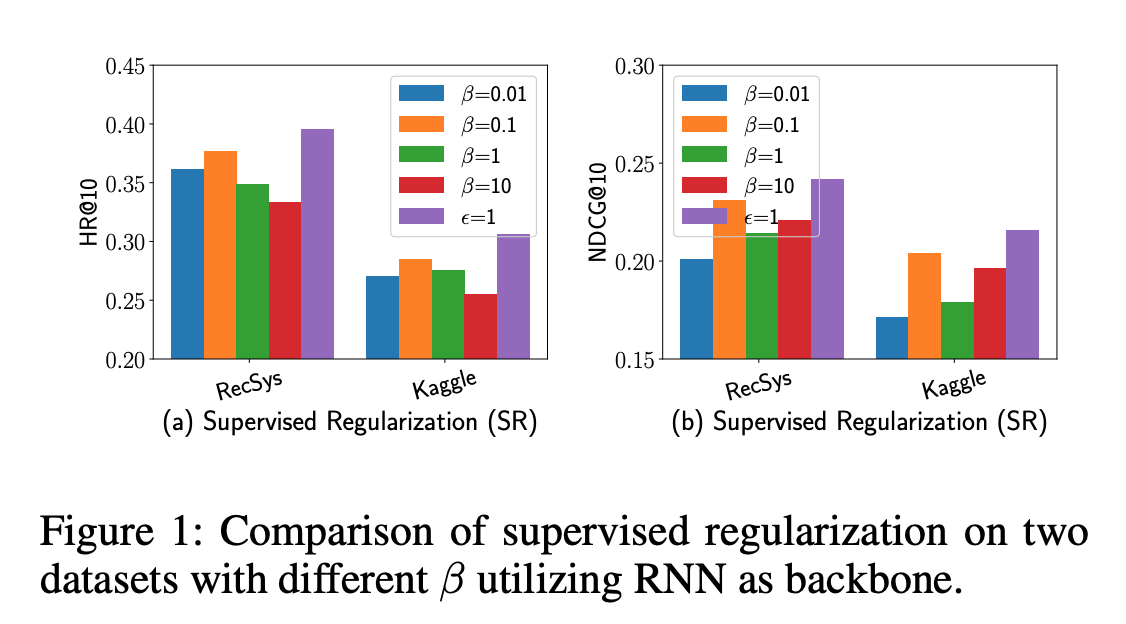
【推荐理由】在本文中,我们首次提出了对线下学习互动推荐的全面分析。我们首先将交互式推荐形式化为一个概率推理问题,然后提出了一个随机和离散的强化学习算法来最大化用户的累积奖励。为了有效地进行离线学习,我们提出了一个通用的离线学习框架来最小化记录策略和学习策略之间的分布不匹配,包括支持约束、监督正则化、策略约束、双重约束和奖励推断。我们在两个真实世界的数据集上进行了广泛的实验,证明了所提出的方法可以取得比现有方法更好的性能
本文研究了在线环境下,从记录的反馈中学习交互式推荐系统的问题,没有任何探索。我们通过提出一个通用的离线强化学习推荐框架来解决这个问题,该框架可以在不进行在线探索的情况下实现用户累积奖励的最大化。具体来说,我们首先介绍了一个交互式推荐的概率生成模型,然后提出了一个有效的推理算法,用于基于记录反馈的离散和随机的策略学习。为了更有效地进行离线学习,我们提出了五种方法来最小化记录政策和推荐政策之间的分布不匹配:支持约束、监督正则化、策略约束、双重约束和奖励推断。我们在两个公开的真实世界数据集上进行了广泛的实验,证明了所提出的方法可以取得比现有的监督学习和强化学习方法更优越的推荐性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢