
4月26日,华为诺亚方舟实验室与中央软件院MindSpore团队等多部门,同鹏城实验室、北大等联合发布「盘古α」,这是业界首个2000亿参数中文预训练模型!
- 详细技术报告:https://arxiv.org/abs/2104.12369
- 代码/模型Gitee开源地址:https://gitee.com/mindspore/mindspore/tree/r1.2/model_zoo/official/nlp/pangu_alpha
- 代码/模型OpenI启智开源地址:https://git.openi.org.cn/PCL-Platform.Intelligence/PanGu-AIpha
2020 年 5 月,OpenAI 发布了 1750 亿参数的自回归语言模型「GPT-3」,在人工智能领域掀起了一阵巨浪。2020年11月,北京智源研究院发布了国内首个26亿参数以中文为核心的大规模预训练语言模型「悟道·文源」。2021年4月12日NVIDIA在arXiv的论文中展示了对万亿级语言模型进行分布式训练的探索。2021年4月19日,阿里达摩院发布了中文预训练语言模型PLUG,该模型参数规模达 270 亿。
由华为诺亚方舟实验室、华为中央软件院、鹏城实验室以及北京大学相关技术团队组建的中文超大规模预训练语言「盘古α」联合攻关团队,首次基于“鹏城云脑Ⅱ”和国产MindSpore框架(https://mindspore.cn/)的自动混合并行模式实现在2048卡算力集群上的大规模分布式训练,训练出业界首个2000亿超大参数中文预训练模型“盘古α”。
盘古α引入随机词序生成,增加预训练难度,提升模型能力。引入预测模块(Predictor),预训练阶段通过位置向量诱导输出。同时支持理解和生成任务,相比于GPT,盘古α模型设计阶段就考虑了其持续学习演化的能力,一是为了节省计算资源,还支持从顺序自回归模型过渡到随机词序自回归模型的增量训练,不同阶段的持续学习能力让模型具备随机词序的生成,具备更强的NLU能力。
不仅如此,盘古α在模型设计上还引入硬件亲和概念,是算法设计协同华为全栈式软硬件生态(MindSpore+CANN+昇腾910+ModelArts)性能和实力的一次完美亮相,牵引了超大规模自动化并行训练技术走向成熟,是国产全栈式AI基础设施支持2000亿级超大规模语言模型训练的第1次,验证了国产E级智算平台在软硬件协同优化、大规模分布式并行训练等核心关键技术的可行性,形成了国产自主可控的通用超大规模分布式训练基座及相关核心技术。
亮点:
- 业界首个2000亿参数中文自回归语言模型「盘古α」;
- 代码、模型逐步全开源;
- MindSpore超大规模自动并行技术;
- 模型基于国产全栈式软硬件协同生态(MindSpore+CANN+昇腾910);
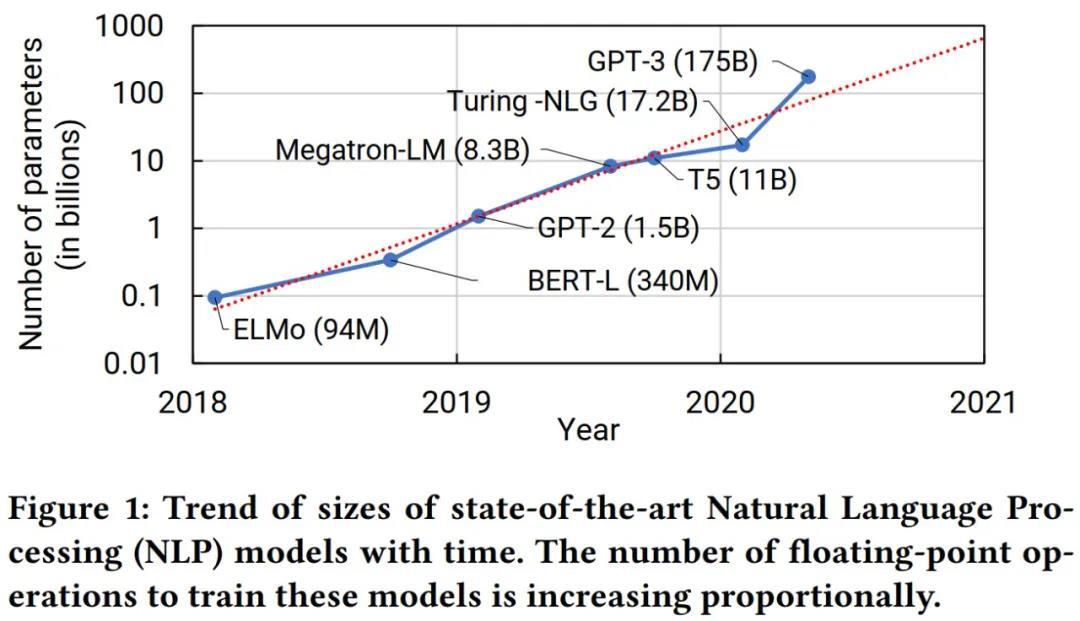
预训练模型如今已经成为深度学习研究中的一种主流范式,国内有学者认为「深度学习已经从『大炼模型』步入到『练大模型』的阶段」,通过设计先进的算法,整合尽可能多的数据,汇聚大量算力,集约化地训练大模型,供大量企业使用,这是必然趋势。
更多内容可以戳原文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢