标题:伦敦玛丽皇后大学、环球音乐集团|MusCaps: Generating Captions for Music Audio(MusCaps:为音乐生成音频字幕)
https://github.com/ilaria-manco/muscaps
https://arxiv.org/pdf/2104.11984.pdf
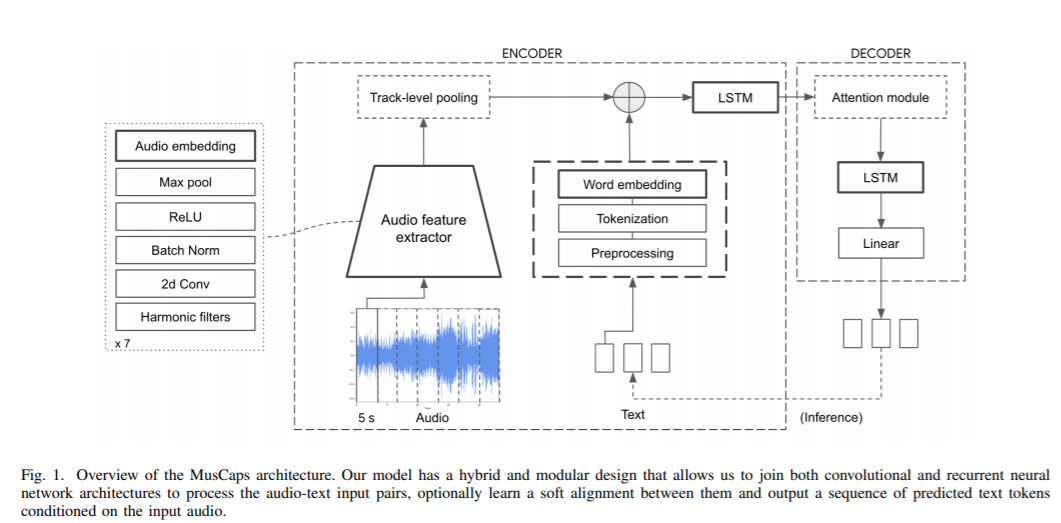
内容中包含的图片若涉及版权问题,请及时与我们联系删除

https://github.com/ilaria-manco/muscaps
https://arxiv.org/pdf/2104.11984.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢