【标题】Where to Go Next: Learning a Subgoal Recommendation Policy for Navigation in Dynamic Environments
【作者团队】Bruno Brito, Michael Everett, Jonathan P. How, Javier Aloson-Mora
【研究团队】Delft University of Technology,Massachusetts Institute of Techology,Aerospace Controls Lab,Cambrige
【论文链接】https://arxiv.org/abs/2102.13073
【发表时间】2021.02.25
【推荐理由】针对导航任务中的子目标推荐。本文提出适用于多智能体环境或人与智能体交互环境的方法。只有具备全局性的导航,智能体才能以局部轨迹优化方法(如MPC)来应对周边智能体的目标不直接可见的缺陷,以及环境条件持续变化等问题。本文对于协作性&非协作性智能体,都通过RL方法训练出网络进行推荐,为MPC规划器提供子目标,为局部规划器提供长期导航,可在其长期目标和与其他智能体交互上性能上持续改善。实验结果表明,该方法极大改善了导航的性能。
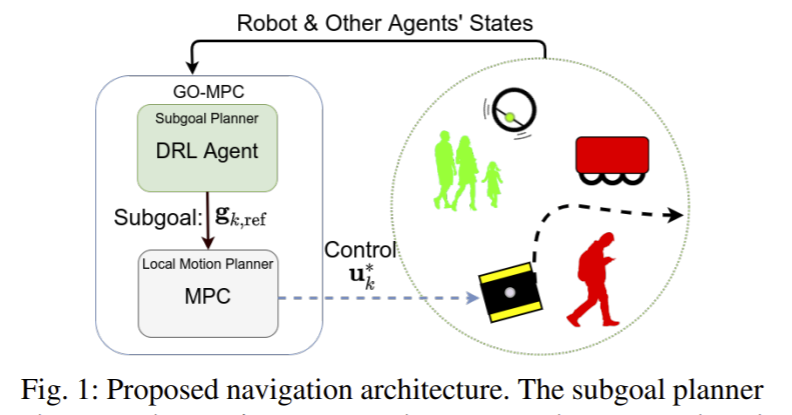
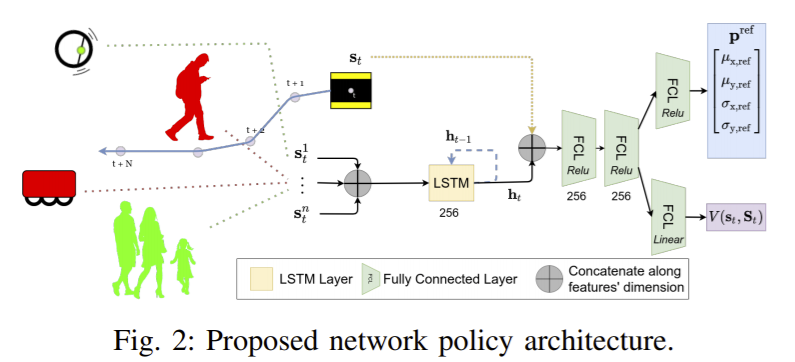
在这种复杂环境中(尤其是在有人参与的多智能体环境中),难点集中在交互式智能体如何规划子目标以更快到达距离较远的全局目标。现有的state-of-art避免碰撞技术都使用了带有线上优化的模型预测控制MPC方法,但进行实时规划的计算开销极大,实用性不强。本文提出的以目标为导向的模型预测控制GO-MPC通过一个学习到的全局导航策略改善了基于优化的在线规划器的性能。RL训练阶段是线下的,智能体学习到一个可利用当前世界信息来为MPC推荐局部子目标的策略。之后,MPC生成能够保证避免碰撞的约束条件的控制命令。本文的方法减少了完成目标的平均时间、提升了成功率。
同时,本文还提出了一个可将RL智能体和基于优化的控制器在混合环境中进行共同训练的算法,可直接在现实硬件上应用,减少了sim2real的隔阂。实验部分将本文方法与两种基准方法的效果进行了对比,分别是一种MPC方法与一种DRL方法,在进行了定量分析与在200种随机场景中的实验,性能提升相当大。实验结果详见论文。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢