
标题:哥本哈根大学|When BERT Plays The Lottery, All Tickets Are Winning(当BERT玩彩票时,所有彩票都中了)
作者:Anna Rogers
机构:哥本哈根大学
- 彩票假说提出,随机初始化的神经网络包含可以单独重新训练以达到(有时甚至超过)完整模型性能的子网络(Frankle and Carbin 2019);
- 可以基于从模型的梯度得出的重要性得分来裁剪大多数BERT的自注意头(Michel,Levy和Neubig 2019);
- 对于受过机器翻译训练的Base-Transformer模型,最后裁剪的头倾向于具有语法功能(Voita等人2019)。
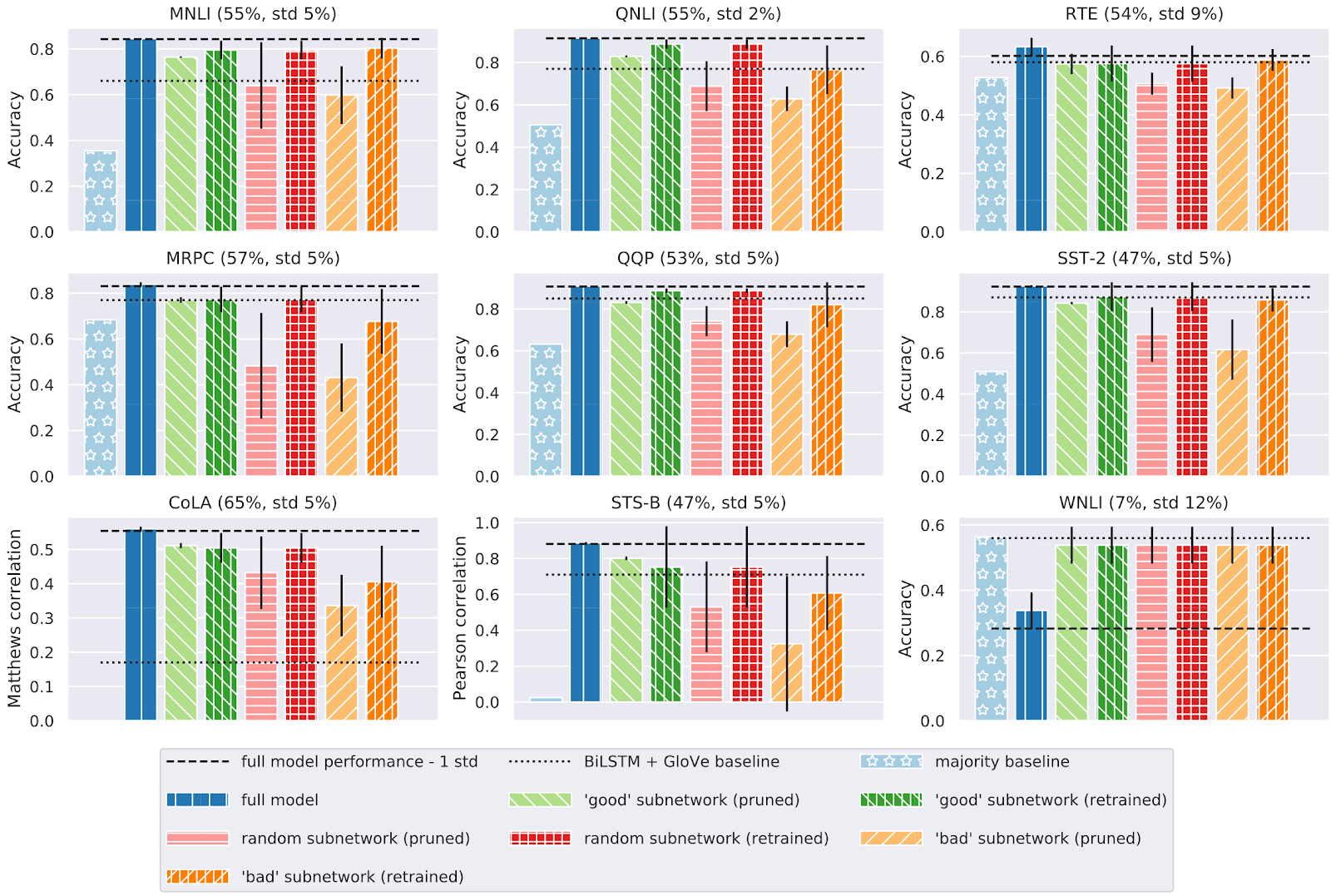
裁剪BERT
跨随机初始化的“好”子网的稳定性如何?
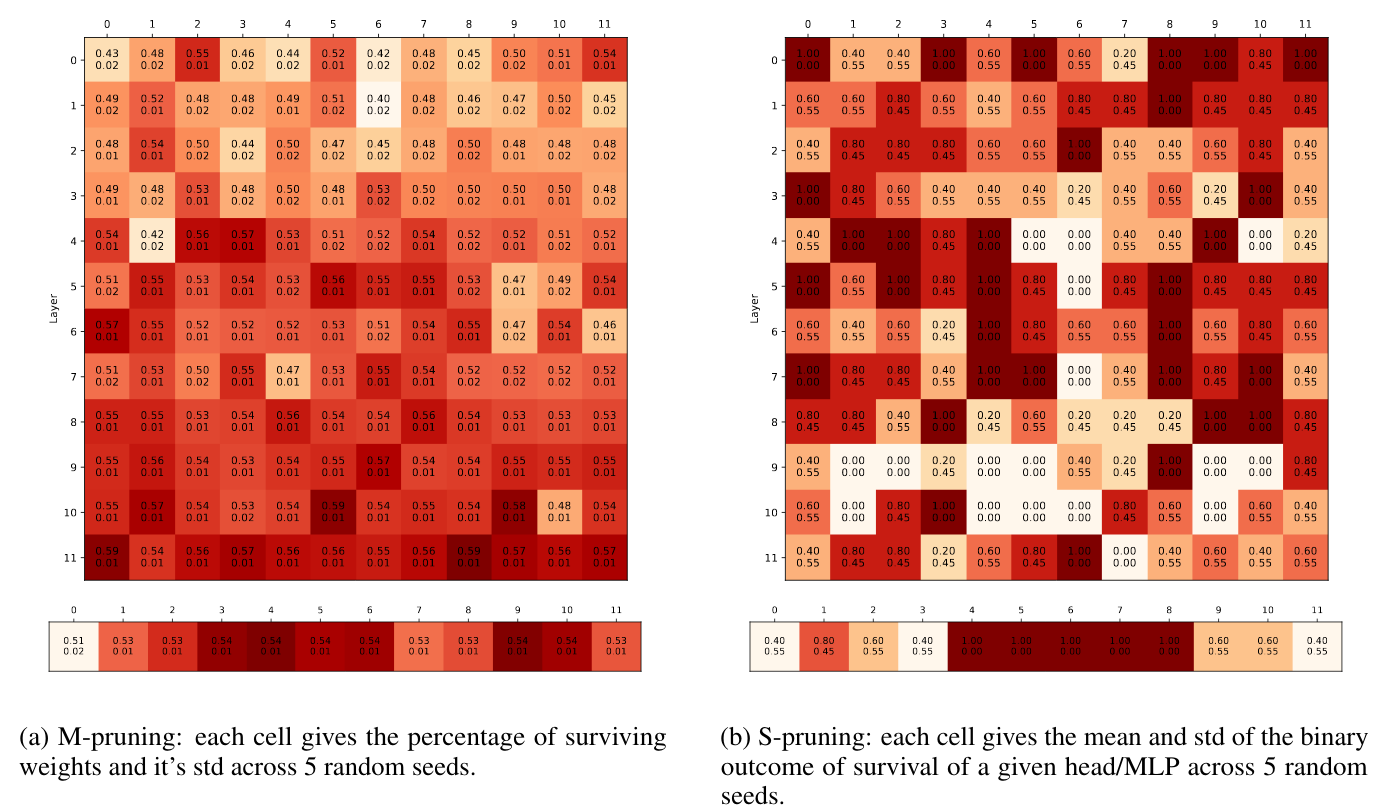
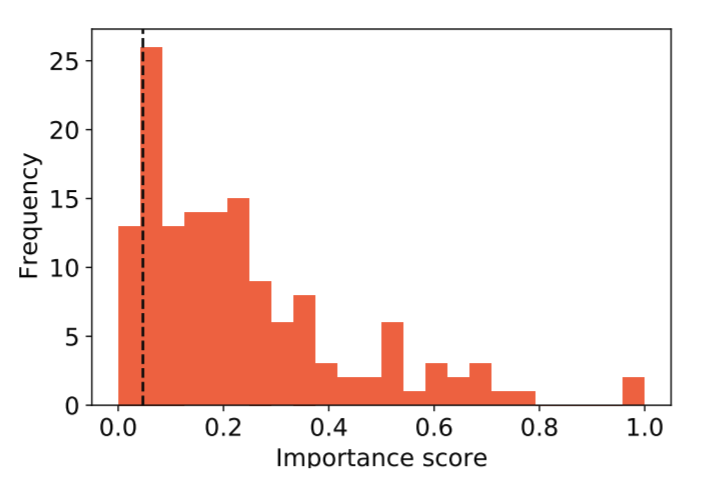
跨任务的“良好”子网的稳定性如何?
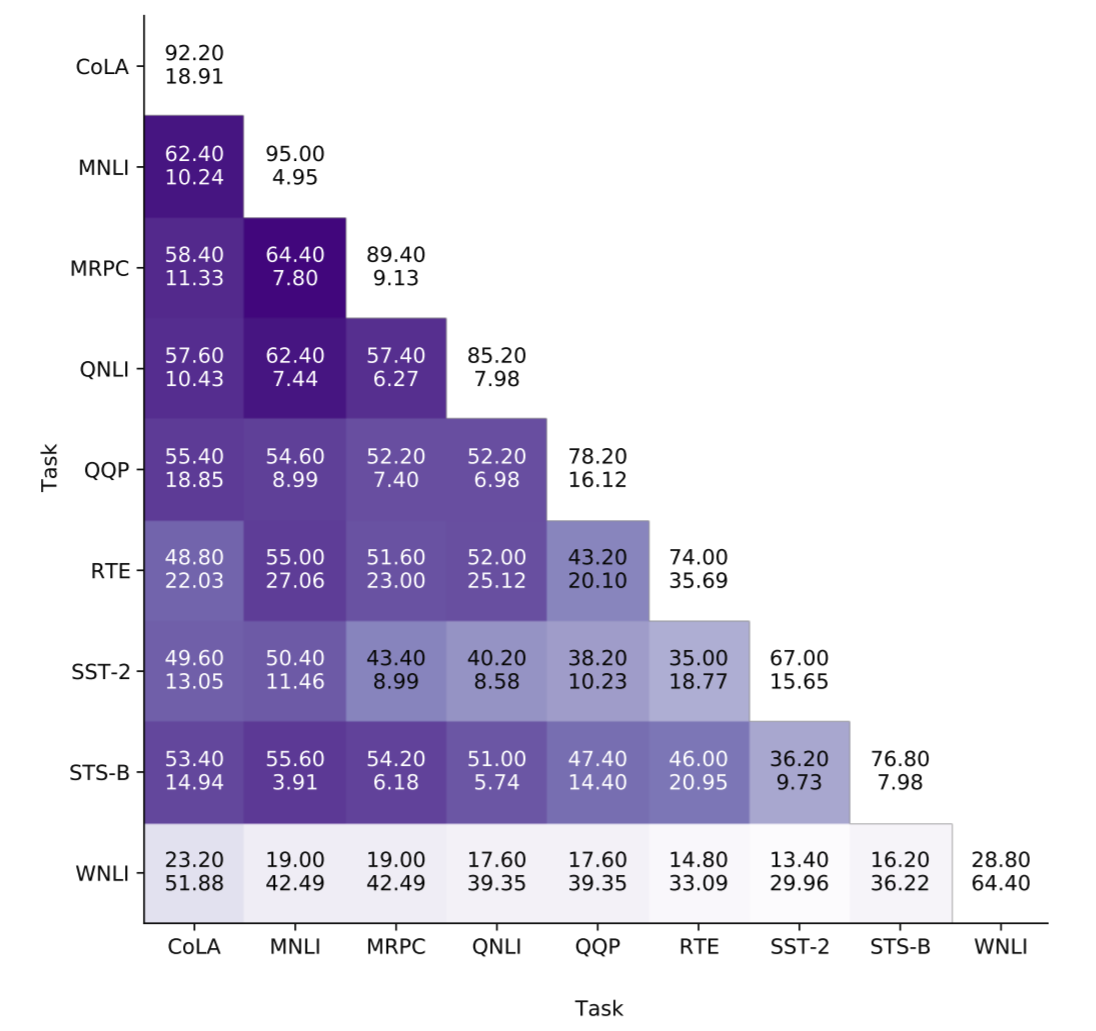
BERT的彩票假设吗?
- “良好”子网:通过s裁剪或m裁剪从完整模型中选择的元素;
- “随机”子网:从完整模型中随机采样的元素,以匹配“良好”子网的大小;
- “不良”子网络:裁剪后没有幸免的元素,再加上从其余元素中采样的一些元素,以匹配良好的子网络规模。
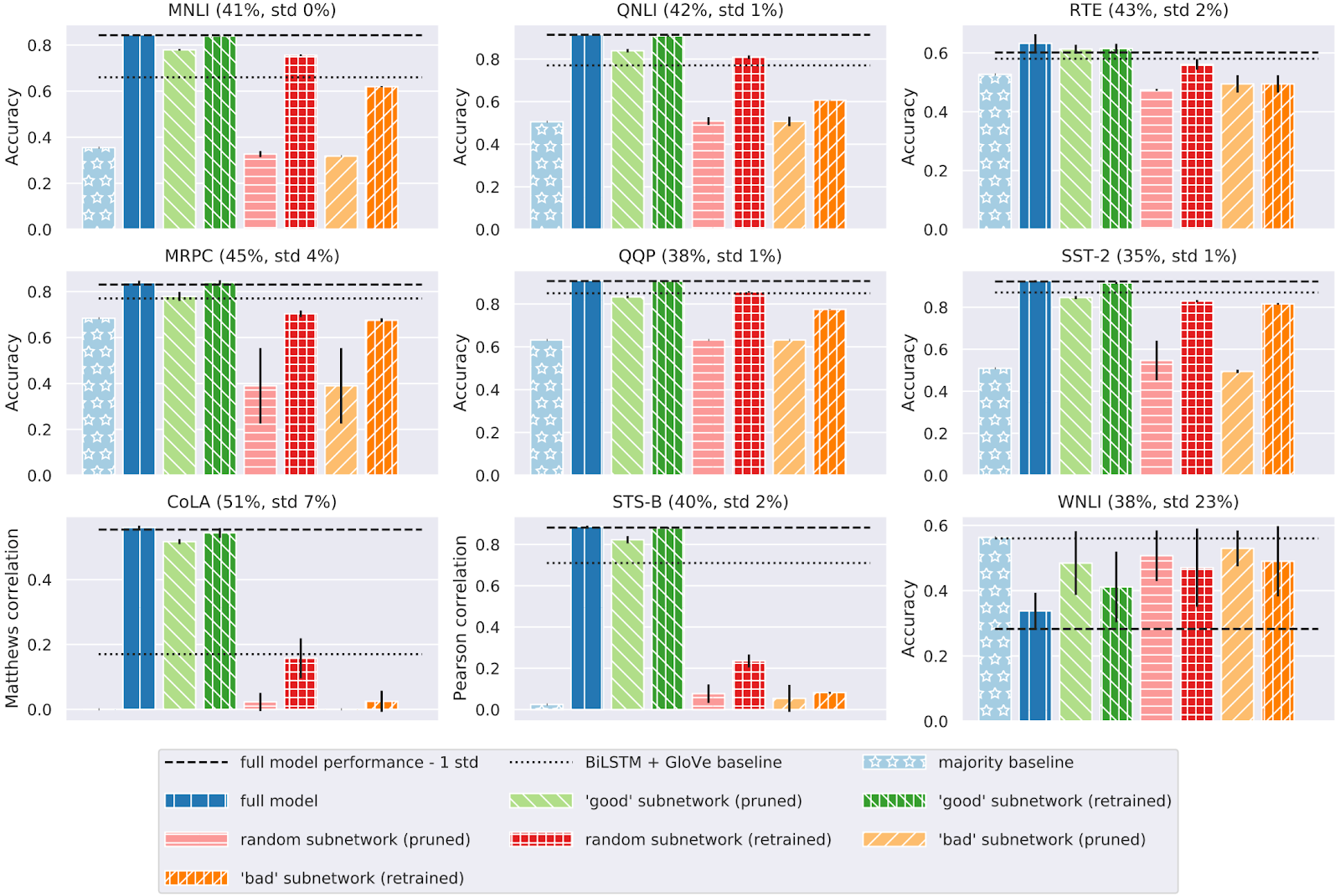
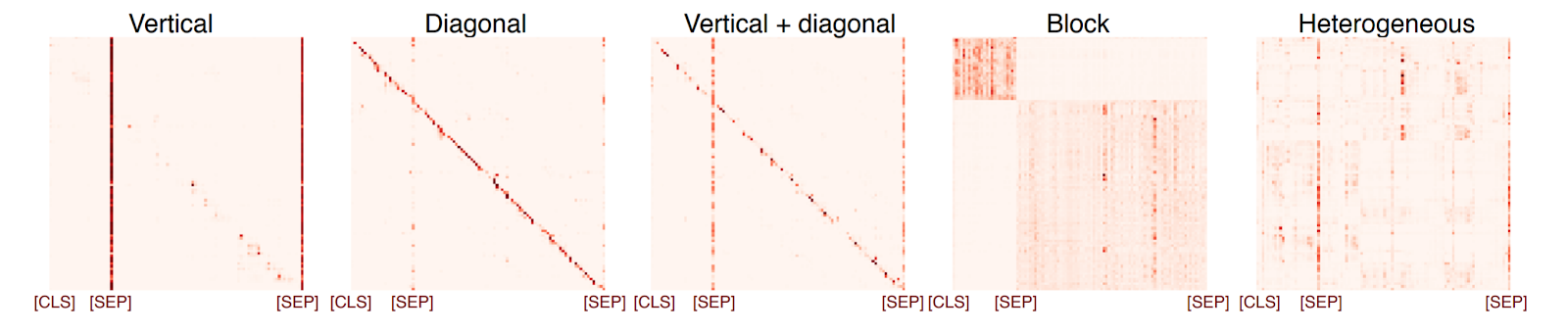
“好”子网的语言学信息如何?
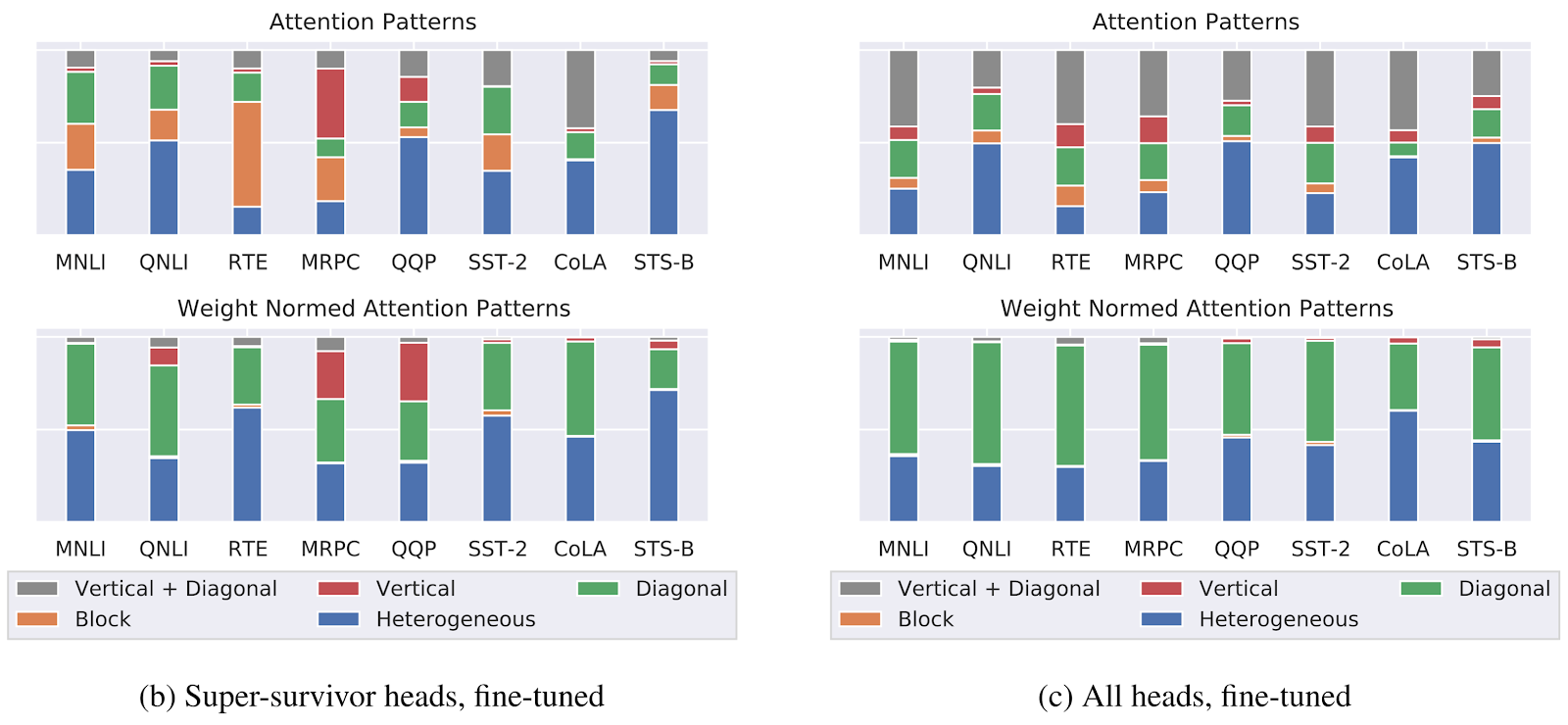
结论
参考文献
Brunner, Gino, Yang Liu, Damián Pascual, Oliver Richter, and Roger Wattenhofer. 2019. “On the Validity of Self-Attention as Explanation in Transformer Models.” arXiv:1908.04211 [Cs], August. http://arxiv.org/abs/1908.04211.
Chen, Tianlong, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. 2020. “The Lottery Ticket Hypothesis for Pre-Trained BERT Networks.” arXiv:2007.12223 [Cs, Stat], July. http://arxiv.org/abs/2007.12223.
Clark, Kevin, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. “What Does BERT Look at? An Analysis of BERT’s Attention.” In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 276–86. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-4828.
Dodge, Jesse, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. 2020. “Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping.” arXiv:2002.06305 [Cs], February. http://arxiv.org/abs/2002.06305.
Ettinger, Allyson. 2020. “What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models.” Transactions of the Association for Computational Linguistics 8: 34–48. https://doi.org/https://doi.org/10.1162/tacl_a_00298.
Frankle, Jonathan, and Michael Carbin. 2019. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” In International Conference on Learning Representations. https://openreview.net/forum?id=rJl-b3RcF7.
Geva, Mor, Yoav Goldberg, and Jonathan Berant. 2019. “Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1161–6. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1107.
Goldberg, Yoav. 2019. “Assessing BERT’s Syntactic Abilities.” arXiv:1901.05287 [Cs], January. http://arxiv.org/abs/1901.05287.
Gururangan, Suchin, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith. 2018. “Annotation Artifacts in Natural Language Inference Data.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 107–12. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/N18-2017.
Hewitt, John, and Christopher D. Manning. 2019. “A Structural Probe for Finding Syntax in Word Representations.” In, 4129–38. https://aclweb.org/anthology/papers/N/N19/N19-1419/.
Htut, Phu Mon, Jason Phang, Shikha Bordia, and Samuel R. Bowman. 2019. “Do Attention Heads in BERT Track Syntactic Dependencies?” arXiv:1911.12246 [Cs], November. http://arxiv.org/abs/1911.12246.
Jain, Sarthak, and Byron C. Wallace. 2019. “Attention Is Not Explanation.” In, 3543–56. https://aclweb.org/anthology/papers/N/N19/N19-1357/.
Jin, Di, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. “Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment.” In AAAI 2020. http://arxiv.org/abs/1907.11932.
Kobayashi, Goro, Tatsuki Kuribayashi, Sho Yokoi, and Kentaro Inui. 2020. “Attention Module Is Not Only a Weight: Analyzing Transformers with Vector Norms.” arXiv:2004.10102 [Cs], April. http://arxiv.org/abs/2004.10102.
Kovaleva, Olga, Alexey Romanov, Anna Rogers, and Anna Rumshisky. 2019. “Revealing the Dark Secrets of BERT.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 4356–65. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1445.
Liu, Nelson F., Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. “Linguistic Knowledge and Transferability of Contextual Representations.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1073–94. Minneapolis, Minnesota: Association for Computational Linguistics. https://www.aclweb.org/anthology/N19-1112/.
McCoy, R. Thomas, Junghyun Min, and Tal Linzen. 2019. “BERTs of a Feather Do Not Generalize Together: Large Variability in Generalization Across Models with Similar Test Set Performance.” arXiv:1911.02969 [Cs], November. http://arxiv.org/abs/1911.02969.
McCoy, Tom, Ellie Pavlick, and Tal Linzen. 2019. “Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3428–48. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1334.
Michel, Paul, Omer Levy, and Graham Neubig. 2019. “Are Sixteen Heads Really Better Than One?” Advances in Neural Information Processing Systems 32 (NIPS 2019), May. http://papers.nips.cc/paper/9551-are-sixteen-heads-really-better-than-one.
Papadimitriou, Isabel, and Dan Jurafsky. 2020. “Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models.” arXiv:2004.14601 [Cs], September. http://arxiv.org/abs/2004.14601.
Rogers, Anna, Olga Kovaleva, Matthew Downey, and Anna Rumshisky. 2020. “Getting Closer to AI Complete Question Answering: A Set of Prerequisite Real Tasks.” In Proceedings of the AAAI Conference on Artificial Intelligence, 8722–31. https://aaai.org/ojs/index.php/AAAI/article/view/6398.
Rogers, Anna, Olga Kovaleva, and Anna Rumshisky. 2020. “A Primer in BERT学: What We Know About How BERT Works.” (Accepted to TACL), February. http://arxiv.org/abs/2002.12327.
Sugawara, Saku, Kentaro Inui, Satoshi Sekine, and Akiko Aizawa. 2018. “What Makes Reading Comprehension Questions Easier?” In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 4208–19. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/D18-1453.
Tenney, Ian, Dipanjan Das, and Ellie Pavlick. 2019. “BERT Rediscovers the Classical NLP Pipeline.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4593–4601. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1452.
Voita, Elena, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. “Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 5797–5808. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1580.
Wang, Alex, Amapreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 353–55. Brussels, Belgium: Association for Computational Linguistics. http://aclweb.org/anthology/W18-5446.
Wiegreffe, Sarah, and Yuval Pinter. 2019. “Attention Is Not Not Explanation.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 11–20. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1002.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢