标题:谷歌|Zero-Shot Detection via Vision and Language Knowledge Distillation(通过视觉和语言知识蒸馏的零样本检测)
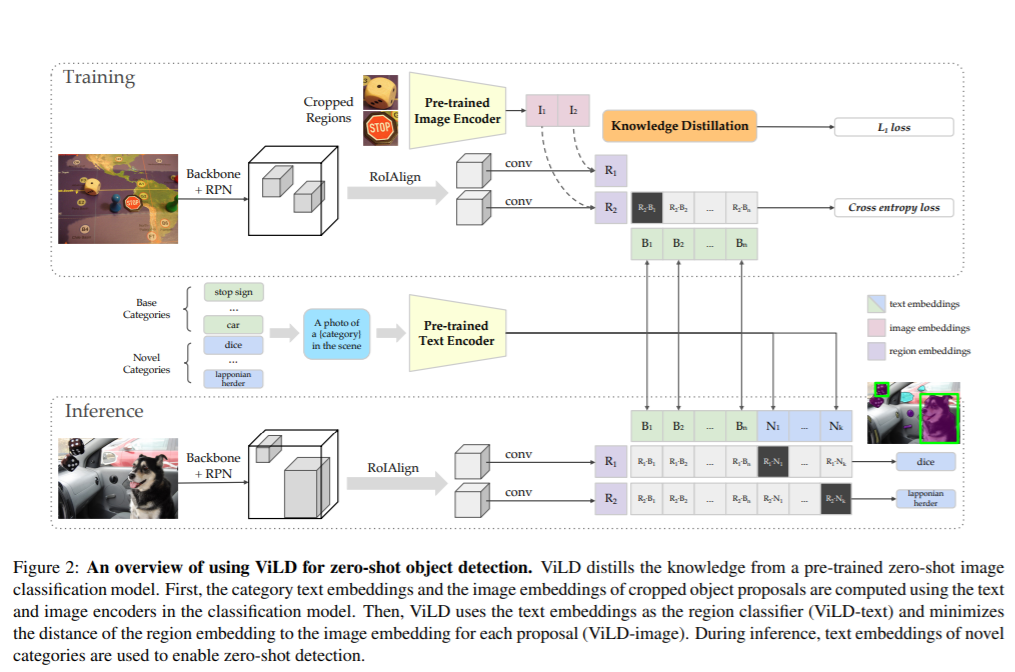
简介:零样本图像分类已大有可为,通过训练对齐的图像和文本编码器来取得进步。这项工作的目标是推进零散物体检测,该目标旨在无边界地检测新颖物体框或蒙版注释。我们提出ViLD,一种通过视觉和语言知识蒸馏的训练方法。我们将知识从预训练的零样本图像分类模型提取为两个阶段检测器。我们的方法将检测器中的区域嵌入到由预训练模型推断出的文本和图像嵌入。我们使用文字嵌入作为检测分类器,通过馈入获得类别名称添加到预训练的文本编码器中。然后我们最小化区域嵌入之间的距离,并图像嵌入,通过馈送区域建议而获得进入预训练的图像编码器在推理过程中,我们将新生成类别的文本嵌入到检测分类器中,以实现零样本检测。我们通过保留所有稀有类别作为新生成的类别,来提高LVIS数据集的性能。
论文下载:https://arxiv.org/pdf/2104.13921v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢