
简介:强化学习与AI游戏:在游戏业AI一般包含了有限状态设计及模糊状态设计两个部分,可以看作为一个包括学习的环境、与环境交互的对象agent、动作以及反馈的决策模型。强化学习在游戏AI中的应用更多时候是为了验证和调试算法模型的准确性,通过传统的简单游戏已经验证了部分强化学习算法。这一类型的游戏我们可以看做是一个由游戏环境画面状态、玩家行为动作和游戏反馈建立的决策模型。
强化学习· 初探
强化学习是一种重要的机器学习方法,能够控制个体在某个环境下自主行动,并透过和环境之间的互动,个体可以不断改进自身的行为。目前各种类型游戏都包含一些人工智能(AI)的运用,一些游戏开发商认为从简单的追逐和逃避在内的一切运动模式,以及神经网络和遗传算法都算游戏 AI 的一部分,在游戏业AI 一般包含了有限状态设计及模糊状态设计两个部分,指导思想就是用最简单的方法,占用最少的资源,去造成假象,让玩家觉得游戏 AI 水平高超。
强化学习· 现状
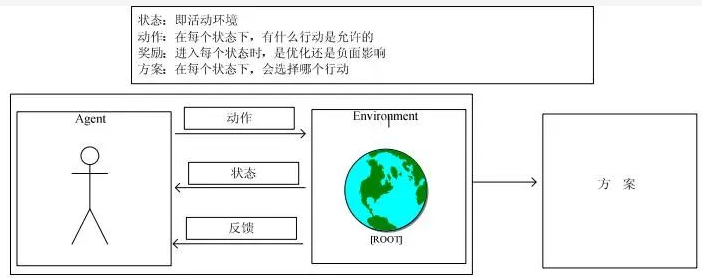
强化学习理论发展可以追溯到动物学习、参数扰动自适应控制等,可以看作为一个包括学习的环境、与环境交互的对象 agent、动作以及反馈的决策模型。RL 其实就是一个连续决策的过程,最终期望学得一个最优策略。决策模型中需要数据以及 training来支持决策,它的数据是序列的、交互的、并且还是有反馈的,包含输入和输出两部分,其中输入是状态、动作和奖励,输出就是方案。
强化学习· 应用
一、强化学习在迷宫类游戏中的应用
理论上,对于有明确目标的算法模型都可以用强化学习来尝试,如游戏 AI。不过实际上,强化学习在游戏 AI 中的应用更多时候是为了验证和调试算法模型的准确性,通过传统的简单游戏已经验证了部分强化学习算法。在迷宫类游戏中,游戏开始进入游戏场景操作画面,玩家所见画面会转化成视觉信号传递回大脑,然后,大脑将视觉信号转换为游戏的语义信息,通过经验指导,将语义信息和应该进行的操作进行映射,再将映射后得到的操作信号传递到身体,表现为一些游戏操作如手指动作。操作结束后,游戏场景画面会变换为玩家奖励画面,让玩家得到相应回报。这一类型的游戏我们可以看做是一个由游戏环境画面状态、玩家行为动作和游戏反馈建立的决策模型:状态看为是迷宫中的一对坐标位置如:起始点(1,1),动作看做是在迷宫中在当前坐标上,玩家可以行走的方向如:{上,下,左,右},反馈看做当前的状态下,迷宫中的这个坐标可能有的奖励或者伤害,最后得出方案即对给定的每一个状态,都会给出一个行动。这里只要动作、行动和反馈是由玩家设定的,方案就可以用算法自动计算出来。
二、强化学习在一些动作类游戏中的应用
在一些动作类游戏中,从游戏开始到玩家捕捉画面,再到大脑反馈信息得到操作指令进行操作的过程和迷宫类游戏相似。在这里让机器代替玩家的话,agent 需要学习到上一场景反馈的信息经验,根据信息经验结合视觉信号处理和理解后的结果,选择合理的动作,然后动作再反馈到游戏中。这里就会得到一系列的状态集合、动作集合、以及动作的反馈。强化学习的过程是一种随机过程,意即整个决策的过程都是有概率特性的,每一步的选择都不是确定的, 而是在一个概率分布中采样出来的结果。因此,整个动作的反馈是一种沿时间轴进行的时序/路径积分。接下来,就是寻找一种状态到动作的映射最优策略。我们的目的是,找到一种最优策略,使得遵循这种策略进行的决策过程,得到的全局回报最大。所以,RL 的本质就是在这些信号下找到这个最佳策略。
三、强化学习在即时战略类游戏中的一些应用
虽然通过传统的简单游戏已经验证了部分强化学习算法、但是对于魔兽争霸、dota 这种即时战略类游戏,其算法设计将复杂,在游戏中训练出策略方案来指导游戏 AI 的难度的就非常大,但是也可以从算法的思路方面进行一些思考。首先,AI 的行为是动态、有记忆的,是能基于新的环境信息做调整的。在即时战略类游戏中的大部分怪物行为都是预先设定的,可以看做大量逻辑的堆积,我们如何进行深度学习让游戏AI 实现获胜呢?在这类型游戏中,一方只能基于友方单位视野看到地图,所以 environment 是部分可见的,这就需要增加一批探索阴影地图的动作。对于状态的抽象描述,可以参考二维矩阵来描述地图,但这类型游戏的复杂在于,不能用单一空间坐标来描述状态环境,状态环境元素至少要包含:各单位的位置和攻击,地图可视范围,各单位目前携带物品及使用范围,各单位现在所学技能等所有会影响行动决定的,需要把这些元素分成不用的层次。对于动作的描述,游戏玩家操作动作往往会有一系列,但这一系列规则是有规律可寻的。在这里可以将一系列的动作作为一个个小的分割目标,进行深度学习优化策略,形成一个操作行为集合即方案集,来达到最终目标。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢