
简介:近年来,自监督的表征学习已经取得了显著的成功。通过颠覆对监督式标签的需求,这些方法能够利用互联网上和摄影数据集中存在的大量无标签图像。然而,为了建立真正的智能体,我们必须构建表征学习算法,它不仅可以从数据集中学习,还可以从环境中学习。在自然环境中的智能体通常不会被给予经过规划的数据,相反,它必须探索它的环境,以获得它要学习的数据。本文对此提出了一个框架,联合学习一个强化学习策略和一个视觉表征模型的好奇的表征学习(CRL)。该策略在预训练中要求最大化表征学习者的错误,并在这样做的过程中被激励去探索其环境。同时,随着策略向它提供越来越难的数据来学习,学到的表征变得越来越强。本文所学到的表征能够很好地转移到下游的导航任务中,在不使用任何监督的情况下,表现得比ImageNet预训练更好或更有可比性。此外,尽管是在模拟中训练的,但本文学习到的表征可以在真实图像上获得可解释的结果。
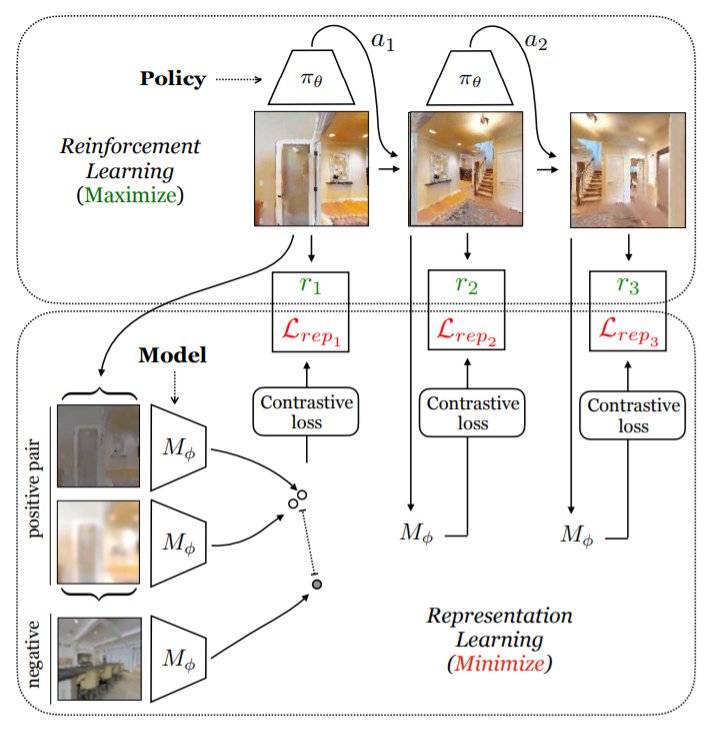
上图为CRL(好奇的表征学习)的概述。本文共同训练一个RL策略和视觉表征学习模型来学习互动环境中的视觉表征。该RL策略和视觉表征学习模型参与到一个mini-max游戏中,该游戏中策略为使奖励(被设定为表征学习模型的损失)最大化,而表征学习模型(本文使用对比学习方法SimCLR)则最小化它自己的损失。图中只展示了第一帧的完整对比性设置,但它适用于每一帧。
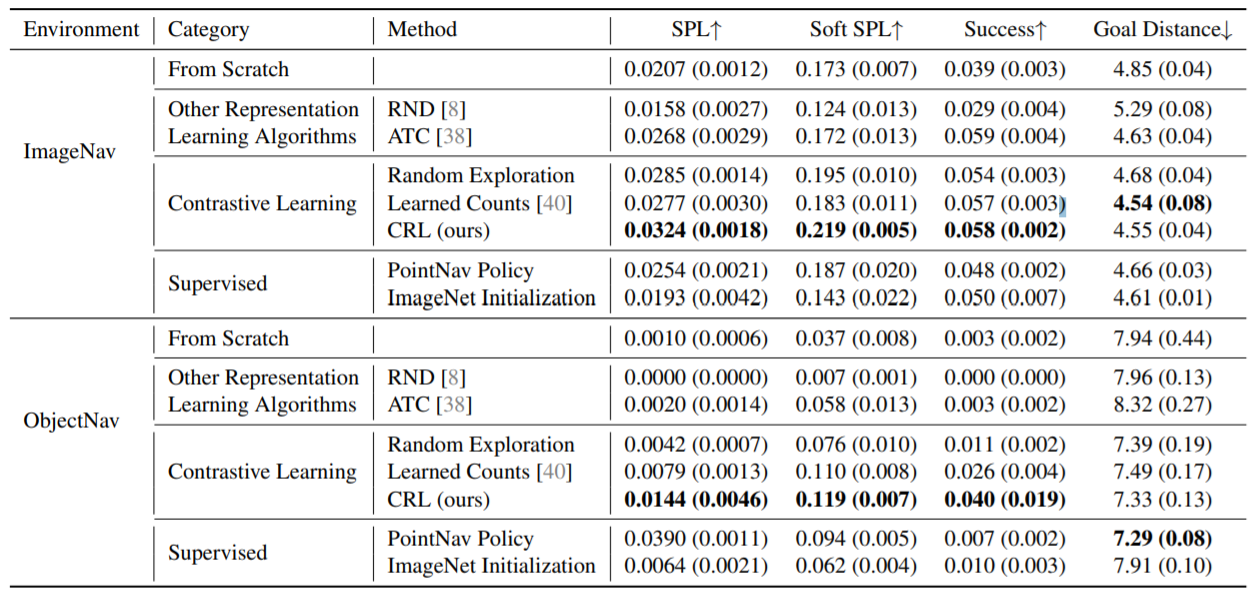
上图为导航与学习的交互式表征的比较的全部结果。 Policies是在ImageNav和ObjectNav任务的测试集上评估的,并在每个环境中训练了1000万帧。我们考虑利用现有的表征学习方法(ATC、RND和对比学习),从头开始训练RL智能体,或利用有监督的权重(PointNav Policy,ImageNet Initialization)。从预训练的权重初始化的RL代理进行了表征冻结,而从头开始的RL代理中的所有权重都是经过训练的。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢