【论文标题】Entailment as Few-Shot Learner
【作者团队】Sinong Wang, Han Fang, Madian Khabsa, Hanzi Mao, Hao Ma
【发表时间】2021/04/29
【机 构】facebook AI
【论文链接】https://arxiv.org/pdf/2104.14690.pdf
【推荐理由】小样本学习新策略
大型预训练语言模型(LMs)作为小样本学习器表现出了非凡的能力。然而,他们的成功在很大程度上取决于模型参数的提升,这使得训练和服务具有挑战性。在本文中,作者提出了一种新的方法,名为EFL,它可以将小的语言模型变成更好的小样本学习器。这种方法的关键思想是将潜在的NLP任务重新表述为一个entailment任务,然后用少至8个例子来微调模型。我们进一步证明我们提出的方法可以 (i) 与基于无监督的对比学习的数据增强方法自然结合;(ii) 容易扩展到多语言的小样本学习。对18个标准的NLP任务进行的系统评估表明,这种方法将现有的各种SOTA几率学习方法提高了12%,并产生了与500倍大的模型(如GPT-3)竞争的小样本性能。
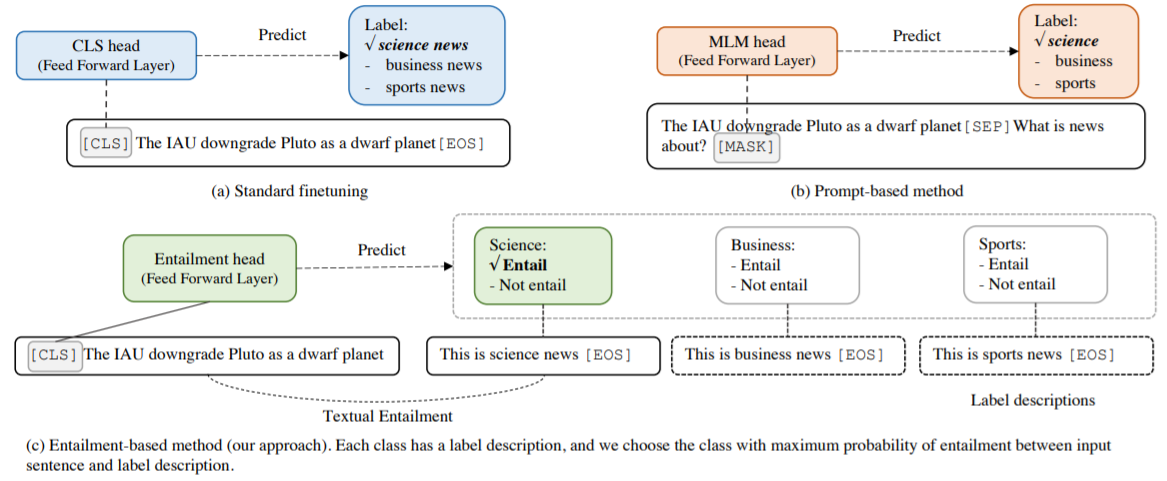
上图为分别为标准微调,基于Prompt的微调和基于Entailment的方法。与基于Prompt的方法相比,Entailment方法的关键区别在于将任务重新表述为含义型任务,而不是完形填空式问题,并设计细粒度的标签描述,而不是单一的任务描述。这中间的关键想法在于将类别标签转换成可用于描述标签的自然语言句子,并确定该句子是否包含标签描述。
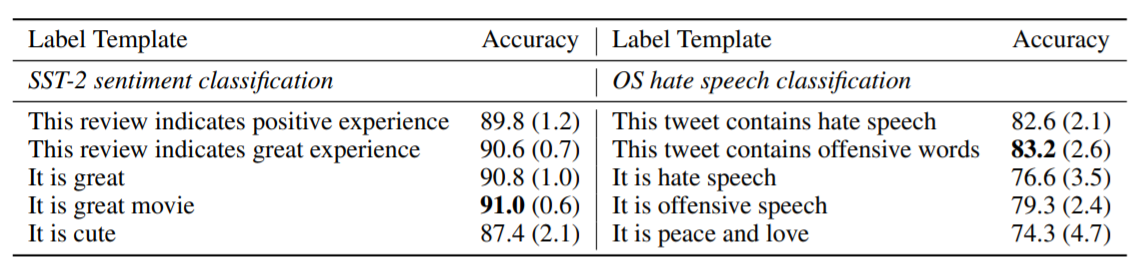
上图展示了标签描述对K=8的EFL方法的影响。如果设计的标签描述与问题定义接近,则性能相对稳定,但如果选择语义不相关的标签描述,则性能退化。
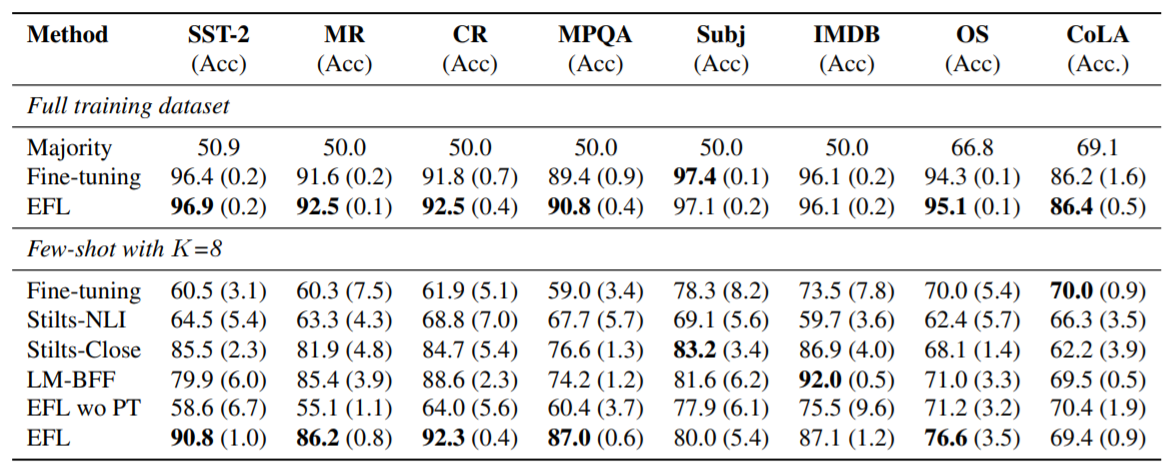
上图为EFL在单句任务上的比较结果。可以看的EFL方法在结合了预训练后,在小样本问题上展示了较好的效能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢