
【标题】Policy Fusion for Adaptive and Customizable Reinforcement Learning Agents
【作者团队】Alessandro Sestini, Alexander Kuhnle, Andrew D. Bagdanov
【研究团队】 Universita degli Studi di Firenze& 剑桥大学
【论文链接】https://arxiv.org/pdf/2104.10610.pdf
【发表时间】2021.4.21
【推荐理由】使用深度强化学习在复杂环境中训练智能代理既困难又耗时,而且需要领域和最先进的深度学习技术的专门知识。本文提出了四种不同的策略融合方法来组合预先训练好的策略,以适应或修改游戏设计变化时的行为–所有这些都不需要重新训练代理来应对这些变化;并进一步显示了如何将这些融合方法与反向强化学习相结合,在不定义新的奖励函数的情况下创建各种复杂的行为。实验表明,熵加权融合(EW)策略的性能明显优于其他策略,并说明了这些方法对于视频游戏的制作和设计者是的确有用。
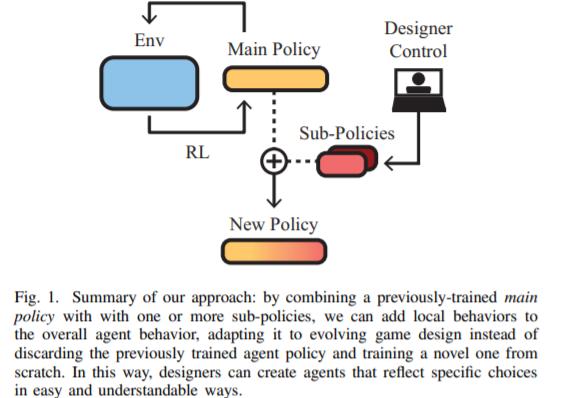
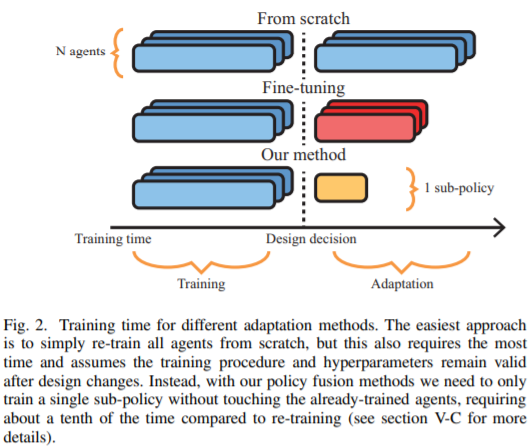
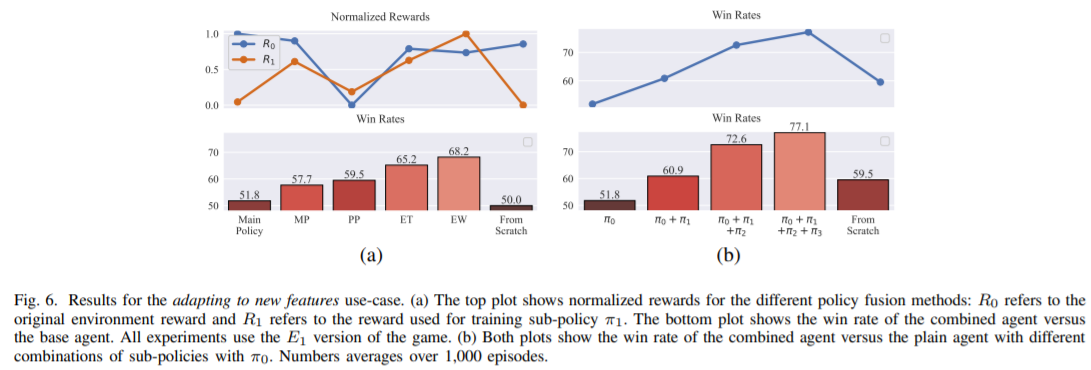
本文研究了以游戏开发为目的,使用强化学习训练智能主体的问题。与替代人类玩家和实现超人类性能的系统不同,本文的代理旨在与玩家产生有意义的互动,同时展示游戏设计者所期望的行为特征。其展示了如何结合不同的行为策略来获得包含所有这些行为的有意义的“融合”策略。为此,本文提出了四种不同的策略融合方法来组合预先训练好的策略。并进一步展示了如何将这些方法与反向强化学习结合使用,以创建具有游戏设计者选择的特定行为风格的智能代理,而不必定义许多可能设计很差的奖励函数。在两种不同环境下的实验结果表明,熵加权策略融合的性能明显优于其他所有策略。本文提供了一些实际示例和用例,来说明这些方法对于视频游戏的制作和设计者是的确有用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢