
【论文标题】MLP-Mixer: An all-MLP Architecture for Vision
【作者团队】Tolstikhin, N Houlsby, A Kolesnikov, L Beyer, X Zhai, T Unterthiner, J Yung, D Keysers, J Uszkoreit, M Lucic, A Dosovitskiy
【机构】谷歌研究院
【论文链接】https://arxiv.org/abs/2105.01601
【代码链接】https://github.com/google-research/vision_transformer
【推荐理由】
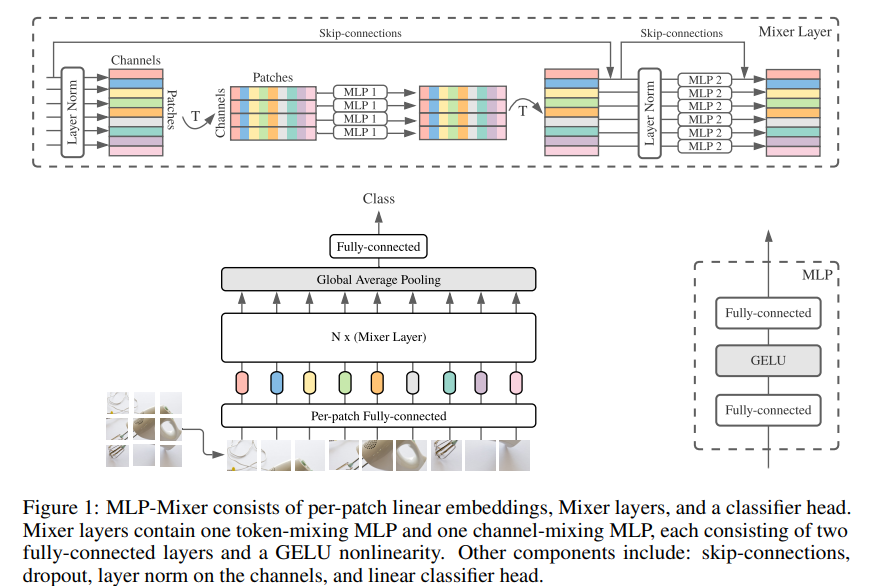
本文来自谷歌研究院。面向计算机视觉任务,作者只使用MLP即可达到与CNN、Transformer相媲美的性能。
卷积神经网络(CNN)是计算机视觉的首选模型。最近,基于注意力的网络,如视觉Transformer,也开始流行起来。虽然卷积和注意力都可以实现良好的性能,但都不是必要的。本文提出MLP-Mixer,一种完全基于多层感知器(MLP)的架构,包含两种类型的层:一种是独立应用于图块的MLP(用于位置级特征"混合"),另一种是跨图块应用的MLP(用于空间信息"混合")。在大型数据集上进行训练,或使用现代正则化方案时,MLP-Mixer在图像分类基准上获得了有竞争力的分数,其预训练和推理的计算资源开销与最先进的模型相当。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢