
【标题】Forgetful experience replay in hierarchical reinforcement learning from expert demonstrations
【作者团队】Alexey Skrynnik, Aleksey Staroverov, Ermek Aitygulov, Kirill Aksenov,Vasilii Davydov, Aleksandr I. Panov
【研究团队】 莫斯科FRC CSC RAS AI研究机构 & 莫斯科物理技术学院
【论文链接】https://doi.org/10.1016/j.knosys.2021.106844
【发表时间】2021.4.22
【推荐理由】深度强化学习(DRL)在复杂的游戏和机器人环境中显示出令人印象深刻的结果。这些结果通常以巨大的计算成本为代价来获得,并且需要在代理与环境之间进行大量的交互。基于此,本文提出了一种新颖的ForgER算法,用于在复杂的部分可观察环境(包括分层设置)中从演示中进行强化学习。该算法可有效地处理专家数据错误,并在根据agent的能力调整动作空间和状态表示时减少了质量损失。实验研究结果表明,ForgER超越了现有的最新RL方法。基于该算法的解决方案在著名的MineRL竞赛中击败了其他解决方案,并允许agent在专家级别演示行为。
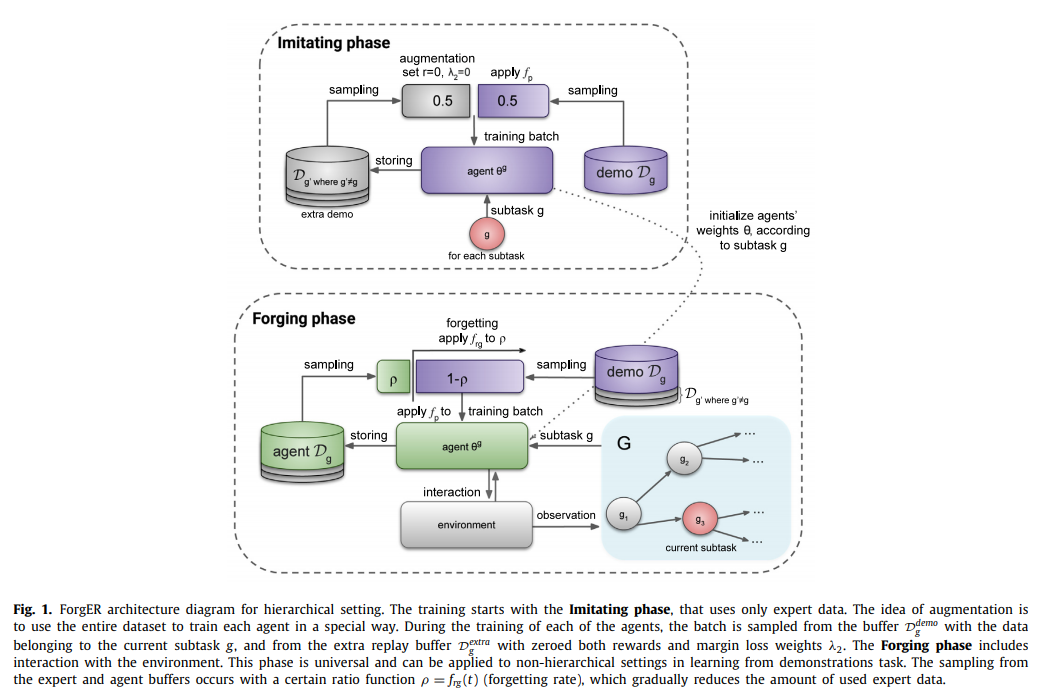
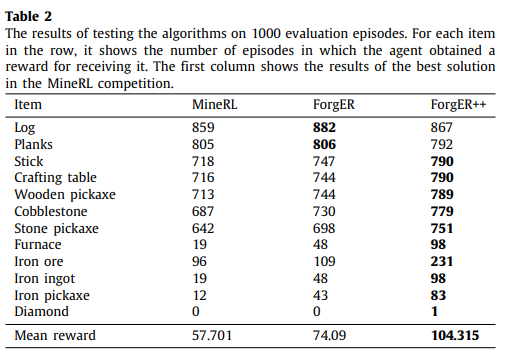
深度强化学习(DRL)在复杂的游戏和机器人环境中显示出令人印象深刻的结果。这些结果通常以巨大的计算成本为代价来获得,并且需要在代理与环境之间进行大量的交互。分层方法和专家演示是提高强化学习方法的样本效率的最有前途的方法之一。本文中提出了一种方法的组合,允许代理在具有多个相关目标的复杂的基于视觉的环境中使用低质量的演示。我们的遗忘经验重放(ForgER)算法可有效地处理专家数据错误,并在根据agent的能力调整动作空间和状态表示时减少了质量损失。所提出的面向目标的重放缓冲区结构使允许代理自动突出显示子目标,以解决演示中复杂的分层任务。该方法具有高度的通用性,可以集成到各种非策略方法中。通过在复杂环境中进行专家演示,ForgER超越了现有的最新RL方法。基于该算法的解决方案在著名的MineRL竞赛中击败了其他解决方案,并允许agent在专家级别演示行为。


内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢