
论文标题:Self-Supervised Multi-Frame Monocular Scene Flow
论文链接:https://arxiv.org/abs/2105.02216
代码链接:https://github.com/visinf/multi-mono-sf
作者单位:达姆施塔特工业大学 & hessian.AI
表现SOTA!性能优于Self-Mono-SF、EPC++等网络,代码刚刚开源!
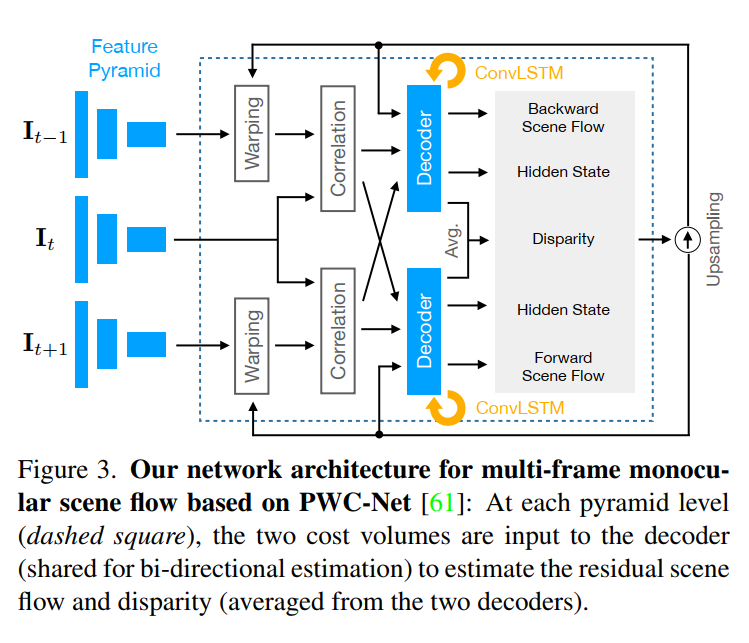
由于简单,经济的捕获设置,从单目图像序列估计3D场景流已引起越来越多的关注。由于问题的严重ill-posedness,当前方法的准确性受到了限制,尤其是有效的实时方法的准确性。在本文中,我们介绍了一种基于自监督学习的多帧单目场景流网络,在保持实时效率的同时,比以前的网络提高了准确性。基于采用split-decoder设计的高级两帧基线,我们提出(i)使用三帧输入和卷积LSTM连接的多帧模型,(ii)可以识别遮挡的census loss以获得更好的准确性,以及( iii)梯度分离策略,以提高训练的稳定性。 在KITTI数据集上,我们观察到基于自监督学习的单目场景流方法之间的最新准确性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢