
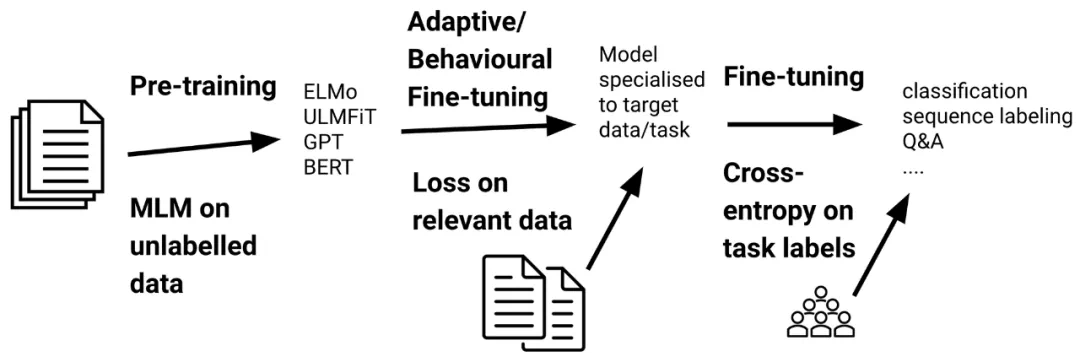
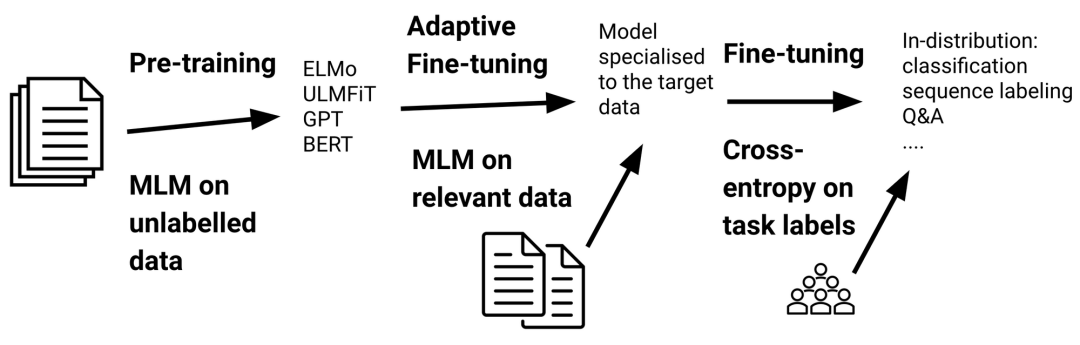
 对预训练语言模型(LM)进行微调已成为在自然语言处理中进行迁移学习的实际标准。在过去三年中(Ruder,2018),微调(Howard&Ruder,2018)已经取代了使用预训练嵌入(Peters 等,2018)的特征提取,而预训练语言模型由于它们提高了采样效率和性能(Zhang 和 Bowman,2018),受到了基于翻译训练的模型(McCann 等,2018)、自然语言推理(Conneau 等,2017)和其他一些任务的青睐。
对预训练语言模型(LM)进行微调已成为在自然语言处理中进行迁移学习的实际标准。在过去三年中(Ruder,2018),微调(Howard&Ruder,2018)已经取代了使用预训练嵌入(Peters 等,2018)的特征提取,而预训练语言模型由于它们提高了采样效率和性能(Zhang 和 Bowman,2018),受到了基于翻译训练的模型(McCann 等,2018)、自然语言推理(Conneau 等,2017)和其他一些任务的青睐。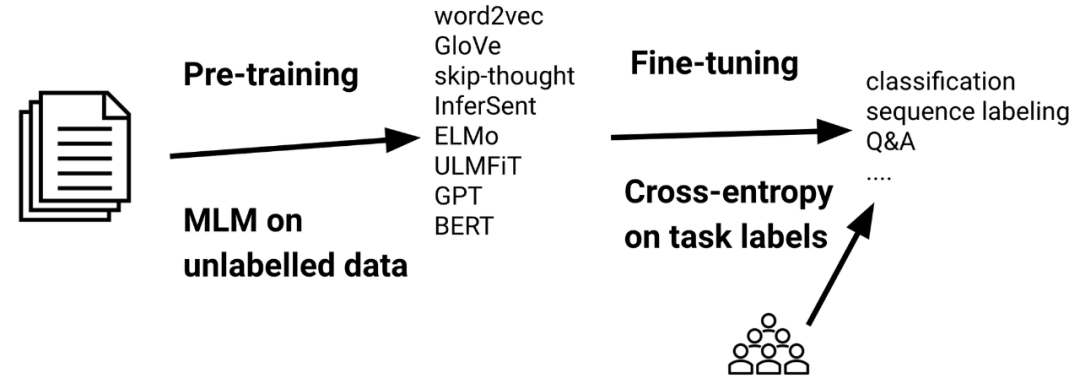
 的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量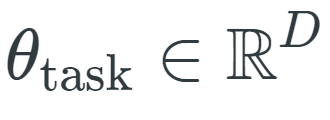 来捕获更改预训练模型参数
来捕获更改预训练模型参数 的方法。微调后的参数是将任务特定的排列应用于预训练参数的结果:
的方法。微调后的参数是将任务特定的排列应用于预训练参数的结果:
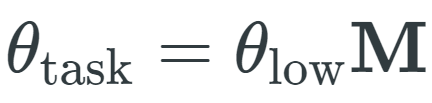 其中,θ_low 是一种低维向量,M 是随机线性投影。
其中,θ_low 是一种低维向量,M 是随机线性投影。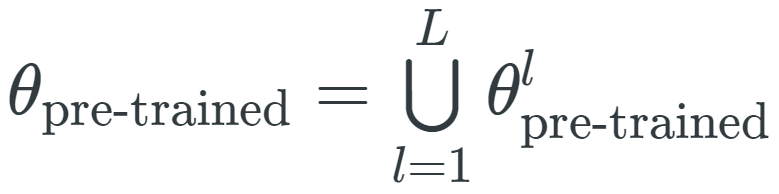 ,其中
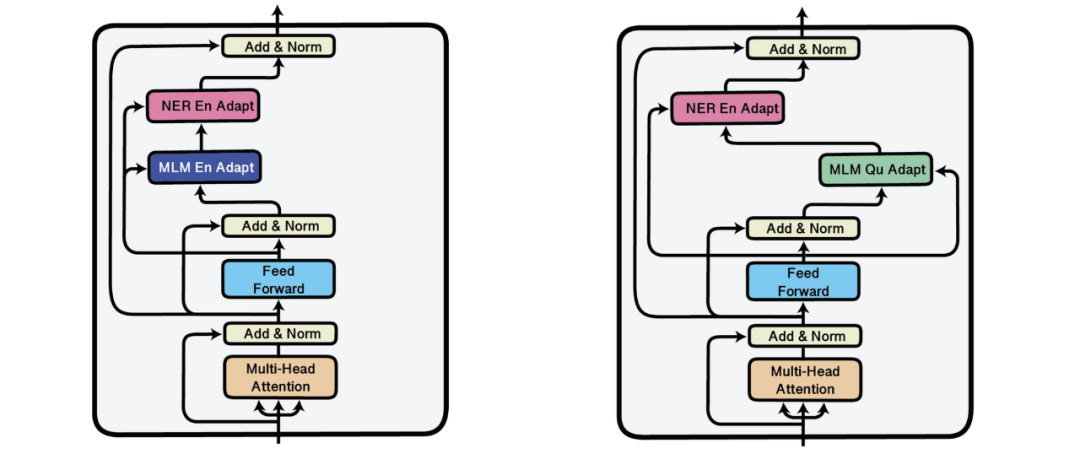
,其中 是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。因此,仅对最后一层进行微调等效于:
是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。因此,仅对最后一层进行微调等效于: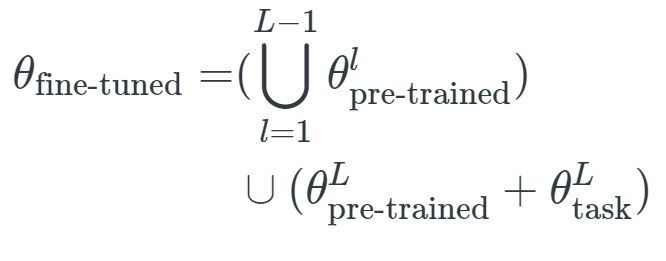
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢