
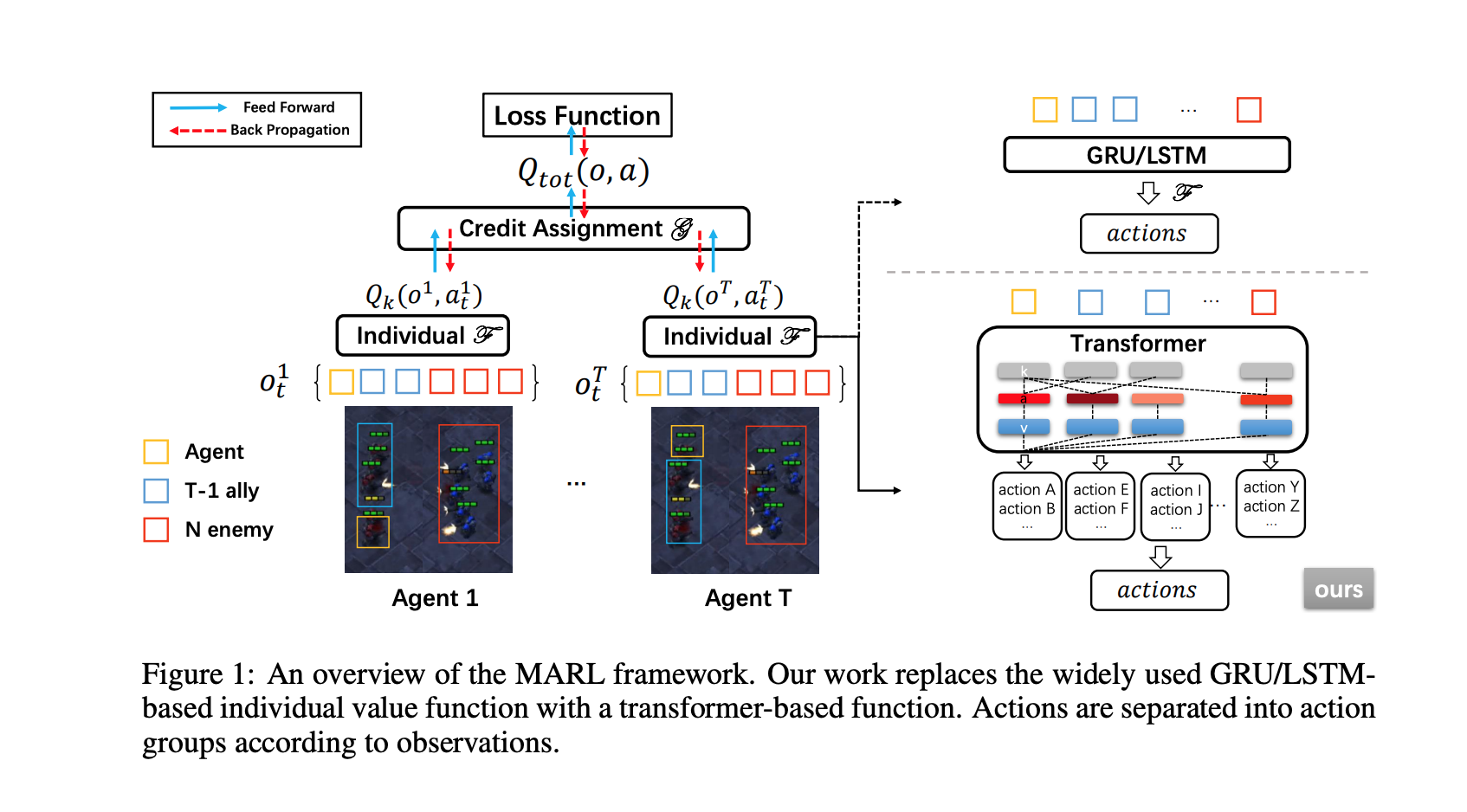
最近在多智能体强化学习方面的进展主要限于为每个新任务从头开始训练一个模型。这种限制是由于 这种限制是由于与固定的输入和输出维度有关的模型结构的限制,这阻碍了经验的积累和所学到的代理在不同难度的任务中的转移。在不同难度的任务中(例如,3对3或5对6的多Agent游戏),代理的经验积累和转移。在本文中,我们首次尝试探索一个通用的多代理强化学习管道,设计一个单一的架构以适应 具有不同观察和行动配置要求的任务。不同于以前基于RNN的模型,我们利用一个基于转化器的模型来产生 一个灵活的策略,通过将策略分布与相互交织的输入观察解耦,使用在自我注意机制的帮助下确定的重要性权重。与标准的变换器块相比,所提出的 模型,我们称之为通用策略解耦转化器(UPDeT),进一步放宽了行动限制,使多Agent任务的决策过程更容易解释。UPDeT具有足够的通用性,可以插入到任何多代理强化学习管道中,并使其具有强大的泛化能力,能够同时处理多个任务。在大规模的SMAC多代理竞争游戏中进行的广泛实验表明 大规模的SMAC多代理竞争游戏,证明了所提出的 基于UPDeT的多代理强化学习相对于最先进的方法取得了显著的改善,在性能和训练方面都表现出了优势的转移 在性能和训练速度方面的优势转移能力(快10倍)。代码发布在在https://github.com/hhhusiyi-monash/UPDeT
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢