
【标题】Exploiting Multimodal Reinforcement Learning for Simultaneous Machine Translation
【作者团队】Julia Ive, Andy Mingren Li, Yishu Miao, Ozan Caglayan, Pranava Madhyastha, Lucia Specia
【研究团队】帝国理工学院 & 谢菲尔德大学 & 爱尔兰都柏林城市大学
【论文链接】https://arxiv.org/pdf/2102.11387.pdf
【发表时间】2021.2.22
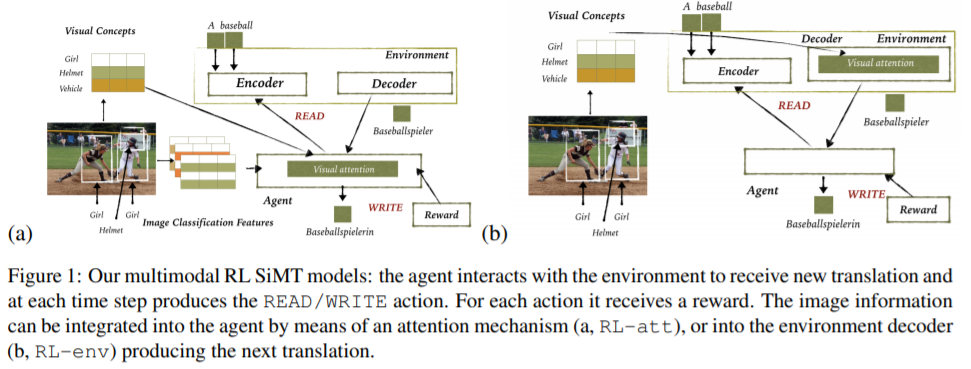
【推荐理由】本文通过探讨两个主要概念来解决同声机器翻译(SiMT)问题:(a)自适应策略,在高翻译质量和低延迟之间找到一个良好的平衡点;(b)通过提供可能产生文本输入之前可用的其他(视觉)上下文信息来支持此过程的视觉信息。 为此,本文提出了一种使用强化学习的多模式方法同声机器翻译方法,该方法具有在代理和环境中集成视觉和文本信息的策略。 并探讨了不同类型的视觉信息和集成策略如何影响同声翻译模型的质量和延迟,并证明了视觉提示可以在保持较低延迟的同时提高翻译质量。
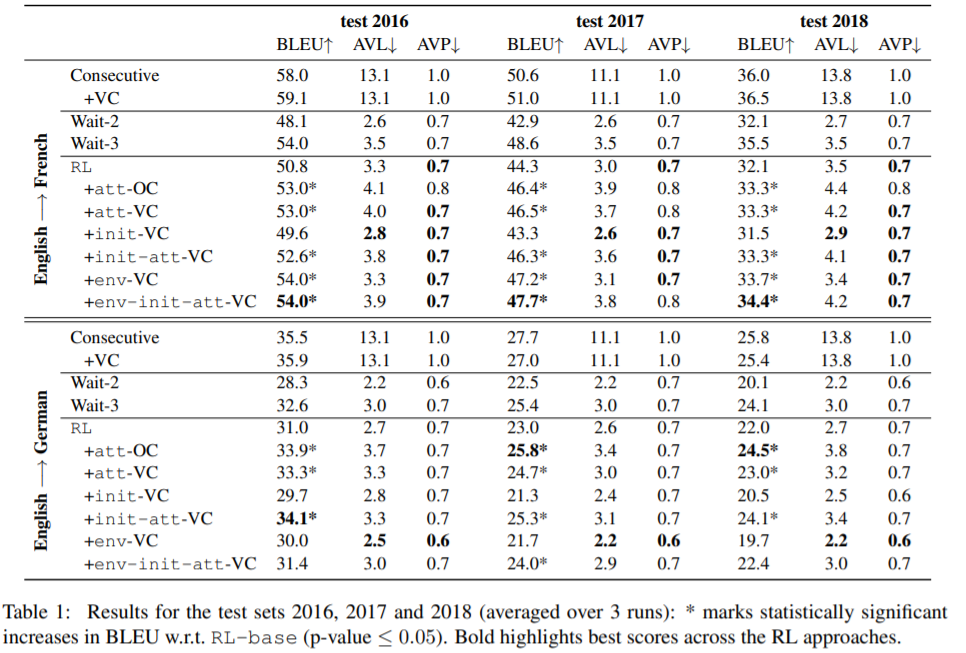
本文提出了第一个全面的阐述多模态强化学习策略的同声传译。首次提出了全面阐述多模态强化学习策略的同时机器翻译。并证明了视觉信息的有效性,并表明它导致自适应策略,该策略在确定性和单峰RL基线上有显著改善。实验结果表明,agent端和环境侧视觉信息都可以用来实现更高质量的、低延迟的翻译。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢