
论文标题:VideoLT: Large-scale Long-tailed Video Recognition
论文链接:https://arxiv.org/abs/2105.02668
作者单位:复旦大学 & 马里兰大学 & IIAI
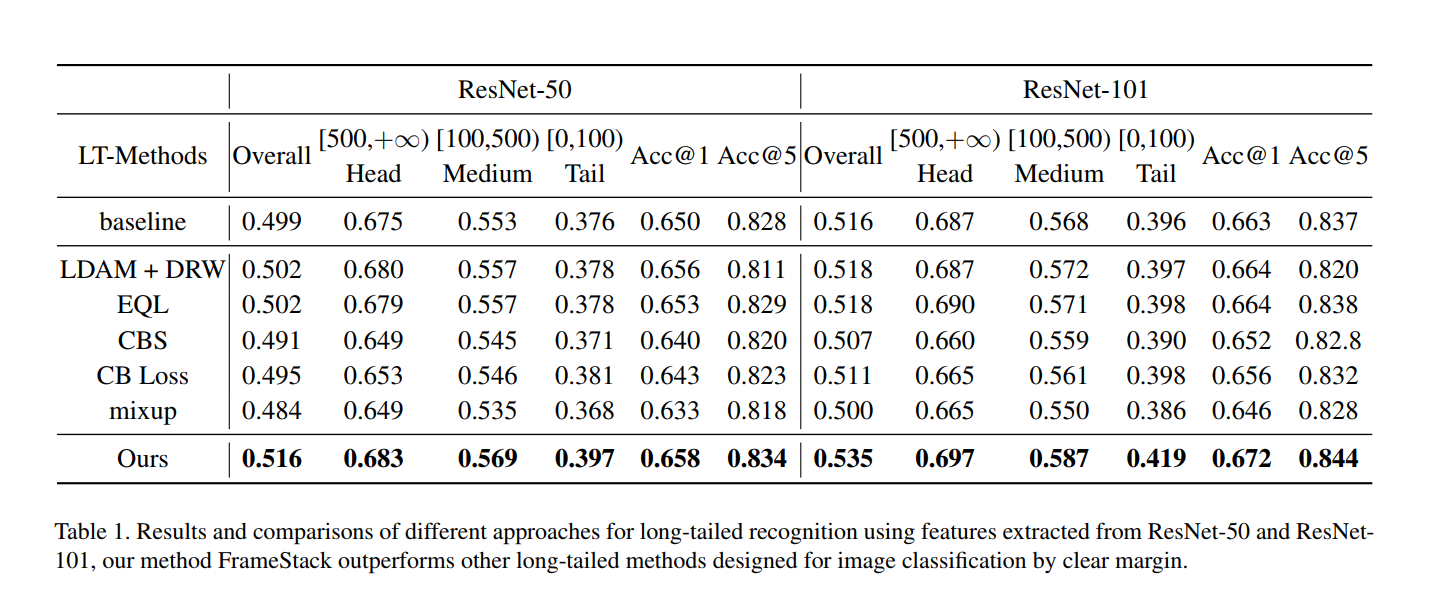
VideoLT:大规模的长尾视频识别数据集,包含256,218个视频,带有长尾分布的共计1,004种标注类别!还提出FrameStack:一种用于长尾视频识别任务的简单而有效的方法。数据集和代码即将开源!
现实世界中的标签分布通常是长尾且不平衡的,从而导致模型偏向dominant labels。虽然长尾识别已被广泛地研究用于图像分类任务,但是在视频领域却做出了有限的努力。在本文中,我们介绍了VideoLT,这是一个大规模的长尾视频识别数据集,是迈向真实世界视频识别的一步。我们的VideoLT包含256,218个未裁剪的视频,注释为1,004类,并有长尾分布。通过广泛的研究,我们证明了由于视频数据中额外的时间维度,用于长尾图像识别的最新方法在视频领域中效果不佳。这促使我们提出FrameStack,这是一种用于长尾视频识别任务的简单而有效的方法。特别是,FrameStack在帧级别执行采样以平衡类分布,并且在训练过程中使用从网络得出的知识来动态确定采样率。实验结果表明,FrameStack可以提高分类性能,而不会牺牲整体准确性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢