
【论文标题】Are Pre-trained Convolutions Better than Pre-trained Transformers?
【作者团队】Yi Tay, Mostafa Dehghani, Jai Gupta, Dara Bahri, Vamsi Aribandi, Zhen Qin, Donald Metzler
【发表时间】2021/05/07
【机 构】Google
【论文链接】https://arxiv.org/pdf/2105.03322.pdf
【推荐理由】预训练中CNN逆袭transformer(emmm)
在预训练语言模型的时代,Transformer是实质上的模型架构的选择。虽然最近的研究展示了卷积和CNN架构的前景,但目前鲜有研究对这些架构的预训练-微调范式进行过探索。在语言模型的背景下,卷积模型在预训练时与transformer相比有竞争力吗?本文研究了这个研究问题,并提出了几个有趣的发现。在8个数据集/任务的一些实验中,作者发现基于CNN的预训练模型是有竞争力的,并且在某些情况下优于它们的Transformer对应模型。总的来说,本文概述的研究结果表明,将预训练和架构方面的进展混为一谈是错误的,这两种进展应该被独立考虑。我们相信我们的研究为替代架构的健康乐观发展铺平了道路。
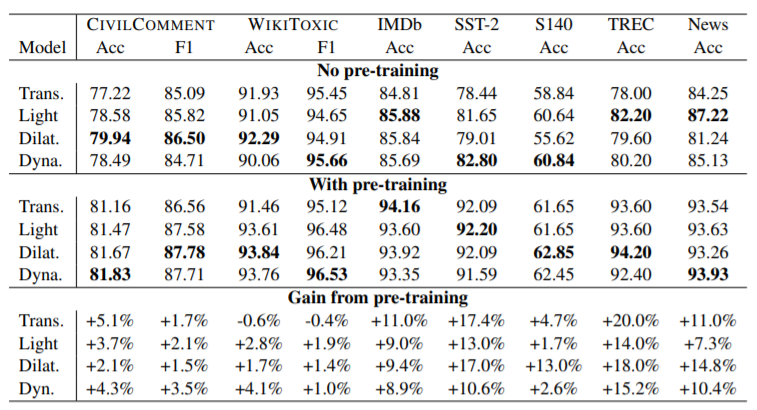
模型在 C4 数据集上进行了预训练,模型参数为大约230M,并且是12层的seq2seq架构以模拟 transformers,使用16 TPU-v3约训练12小时。上图为预训练的卷积架构和预训练的Transformers在攻击性言论检测任务、情感分类、问题分类和新闻分类上的比较结果,该图展示了:
- 在攻击性言论检测任务中,无论是否进行预训练,卷积网络再所有数据集中均优于 transformers
- 在情感分类任务中,IMDB中卷积网络不如 transformers,但是非常接近。但是再其他数据集中卷积网络表现较好,无论是否进行预训练。
- 在问题分类任务中,卷积网络大体上优于 transformers,transformers 从预训练得到的提升更高一些。
- 在新闻分类任务中,与其他类似,卷积网络优于 transformers,dilated卷积受预训练增益最大。
本文的研究结果表明,卷积(1)也受益于预训练,(2)在有预训练和无预训练的情况下,对transformer模型始终具有竞争力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢