
【标题】Reinforcement Learning from Reformulations in Conversational Question Answering over Knowledge Graphs
【作者团队】Magdalena Kaiser, Rishiraj Saha Roy, Gerhard Weikum
【研究团队】德国马克斯-普朗克研究所
【发表时间】2021.5.11
【论文链接】https://arxiv.org/pdf/2105.04850.pdf
【推荐理由】针对现有的知识图(KG)上ConvQA的最新方法只能从流行基准中发现的清晰的问题/答案对中学习,而现实中用户很少会明确地将答案标记为正确或错误的难题。本文提出了Conqer:一种基于RL的KGs会话QA的方法,其中用户以高度口语化和不完整的形式提出特定的后续问题。对于这种ConvQA设置,CONQUER将应答过程建模为多个代理在KG上并行运行,其中运行由使用策略网络采样的动作确定。该策略网络将问题以及对话上下文作为输入,并通过从重新制定可能性中获得的噪声奖励进行训练。通过基于用户研究的基准实验表明,Conqer的性能优于最先进的ConvQA基线,并且Conqer对各种噪声具有鲁棒性。
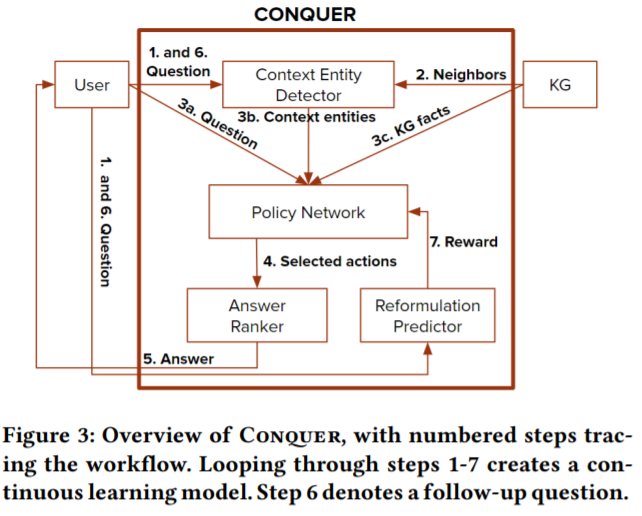
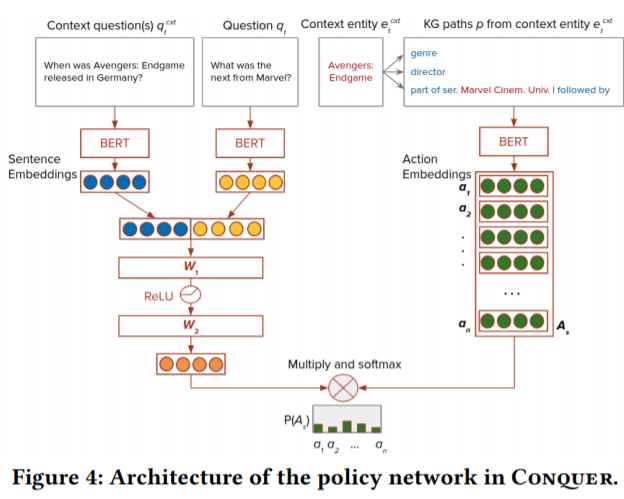
私人助理的兴起使会话问答(ConvQA)成为一种非常流行的用户-系统交互机制。知识图(KG)上ConvQA的最新方法只能从流行基准中发现的清晰的问题/答案对中学习。然而,现实中,很难获得这样的训练数据:用户很少会明确地将答案标记为正确或错误。本文朝着一个更自然的学习范式迈出了一步-从嘈杂和隐式反馈到通过问题重新表述。可能由于错误的系统响应而触发了重新制定,而新的后续问题可能是前一回合答案的积极信号。基于此,本文提出了一种强化学习模型,称为CONQUER,可以从对话性问题和重构中学习。CONQUER将应答过程建模为多个代理在KG上并行运行,其中运行由使用策略网络采样的动作确定。该策略网络将问题以及对话上下文作为输入,并通过从重新制定可能性中获得的噪声奖励进行训练。为了评估CONQUER,本文创建并发布了ConvRef,这是一个基准测试,包含约11k个自然对话,其中包含约20.5万个重新制定的公式。实验表明,CONQUER成功地学习了从噪声的奖励信号中回答对话问题,在最先进的基线上有了显著的提高。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢