【论文标题】Implicit Unlikelihood Training: Improving Neural Text Generation with Reinforcement Learning
【作者团队】Evgeny Lagutin, Daniil Gavrilov, Pavel Kalaidin
【发表时间】2020.01.11
【论文链接】https://arxiv.org/abs/2101.04229
【推荐理由】在语言模型中,研究表明向正则化中加入损失函数可通过协助避免不必要的特征来改善文本生成性能。本文提出了通过使用并优化策略梯度强化学习方法来对语言模型进行微调的方法,以获得更好的生成性能,并用此方法来最小化生成文本中的重复片段。本文提出的隐式非似然训练是一种通过利用策略梯度强化学习方法来微调语言模型的一种正则化输出的算法。实验表明,本文方法在与最小化非似然损失结合时刻减少重复片段并降低困惑度,而对语言模型质量无影响。非似然训练作为为整体框架来使用,以减少在训练负样本过程中产生的不符合目标的文本生成。但有一个很大的问题就是,生成适合特定非似然训练类型的负样本是十分困难的,因此作者改进了传统的非似然训练手段,将其与PG强化学习结合,使其能够隐式的生成负样本。
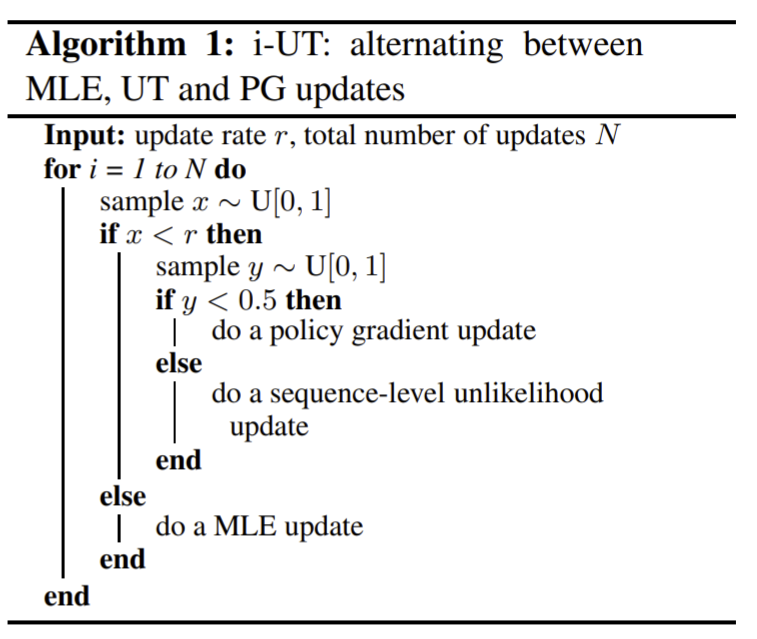
作者的实验包含三个部分的更新,首先是最大化似然MLE,如算法一所示;第二是最小化序列级的非似然损失UL;第三部分是用PG强化学习最小化序列片段,如算法二所示。

实验表明,当在top-p和top-k抽样等辩题上进行小型和中型GPT-2模型的微调时,隐式非似然训练远比其他针对序列片段重复的模型表现出色,同时保持了低困惑度与不重复字词的生成量。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢