简介:华为诺亚方舟实验室在自然语言处理领域的23项研究成果被自然语言处理领域国际会议ACL-IJCNLP 2021(含Findings of ACL)和机器学习领域国际会议ICML 2021录用,研究方向主要涵盖高效预训练语言模型、模型分析和评估、机器翻译和多语言处理、对话与问答系统、预训练理论等。本文将分不同方向,概要介绍其中的部分成果,后续将带来相关研究成果的详细介绍。
高效预训练语言模型
BinaryBERT: Pushing the Limit of BERT Quantization
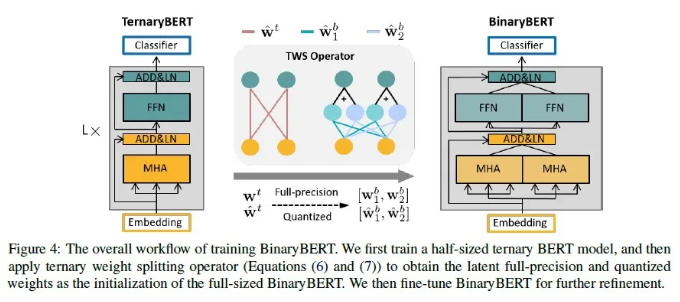
大型预训练语言模型的快速发展极大地推动了对模型压缩的需求,其中量化是一种流行的解决方案。本文提出了Binary-BERT,它通过将模型参数二值化,把BERT量化推到极限。本文发现二值化的BERT比三值化的BERT有更陡峭的损失函数平面,从而使得二值化模型更难于直接训练。因此,我们提出三值化权重分裂的方法,把提前训练好的半宽度下的三值化BERT通过参数裂变的方式得到一个全宽度的二值化BERT。因此,这种二值化模型继承了三值化模型的性能,并且可以通过在分裂后对新结构进行进一步微调来增强效果。实验结果表明,与全精度模型相比,我们的BinaryBERT性能仅略有下降,但尺寸却缩小了24倍,从而得到了GLUE和SQuAD基准数据集上的最新压缩结果。
AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models
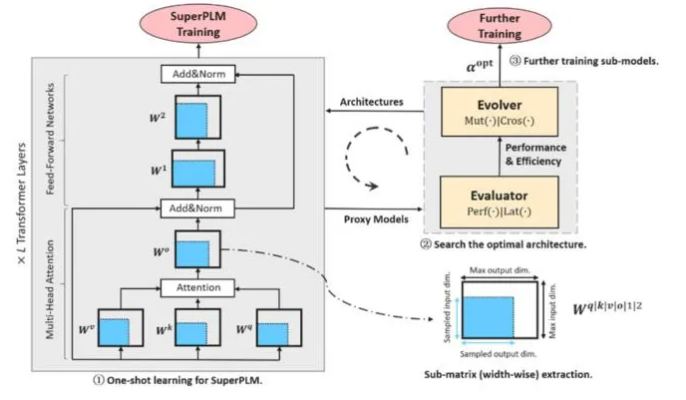
预训练语言模型在自然语言处理领域获得了很大的成功。但目前的预训练语言模型构建大多基于BERT原始的超参数结构设置。我们发现超参数结构对高效类预训练语言模型的性能影响较大,而这类语言模型对资源受限设备上的应用部署有重大意义。因此,我们提出一种面向高效预训练模型的结构搜索方法,所提出方法能够自动搜索出满足特定部署条件(如时延和功耗等)的最优超参数结构。我们在GLUE和SQuAD标注数据集上评测了所提出方法,实验表明AutoTinyBERT超过了基准的搜索方法(如NAS-BERT)和模型压缩的标杆方法(如DistilBERT、TinyBERT、MiniLM和MobileBERT等)。除此之外,通过对搜索得到的模型结构进一步分析,我们提出一种更加高效构建方法,此方法甚至比单个预训练语言模型的构建都快。我们将发布AutoTinyBERT系列的高效预训练模型库满足工业界的不同部署需求。
GhostBERT: Generate More Features with Cheap Operations for BERT
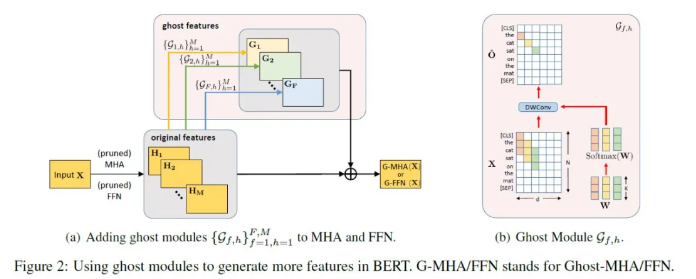
基于Transformer结构的预训练语言模型在各种任务上都取得了突破性的进展。然而Transformer模型参数很多,在对时延和精度有要求的云侧或者端侧作推理有很大挑战。因而,一些研究提出了直接训练小的Transformer模型,或者对一些大型Transformer模型进行压缩的方法。然而当压缩比很大的时候模型效果下降会比较明显。在本文中,我们提出了适用Transformer模型的Ghost模块及其使用方法。它可以配合普通的或者压缩后Transformer模型,从现有的特征中以非常便宜的操作生成更多特征。当用在普通的Transformer模型上时,只需增加极少量的参数和计算,就可以提升模型的性能。当用在压缩后的Transformer模型上时,可以提升模型性能,超越其他的一些高效Transformer模型,在移动设备上进行快速推理。三个主干模型(BERT,RoBERTa和ELECTRA)在GLUE基准数据集上的在上的经验结果验证了提出的GhostBERT的有效性。
SparseBERT: Rethinking the Importance Analysis in Self-attention
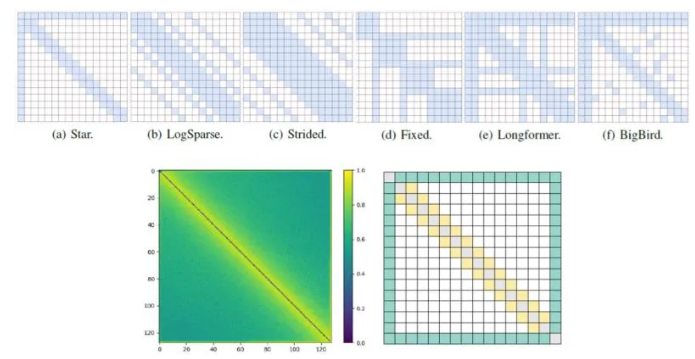
作为Transformer中重要的结构,self-attention一直是研究的热点。之前的工作往往是通过可视化预训练好的Transformer模型来分析注意力矩阵中共同的模式,并基于此提出了一系列稀疏的注意掩码。本文在预训练时动态地研究了注意力矩阵地变化并重新思考了self-attention中位置的重要性。其中一个有趣的结论是注意力矩阵的对角线元素和其他位置相比是最不重要的。为了解释这个现象,我们从通用近似定理的角度上证明了这些位置是可以被舍弃的。为了进一步降低self-attention的计算复杂度,我们提出可微分注意掩码(DAM)算法,可以用于指导 SparseBERT的设计。
模型评估
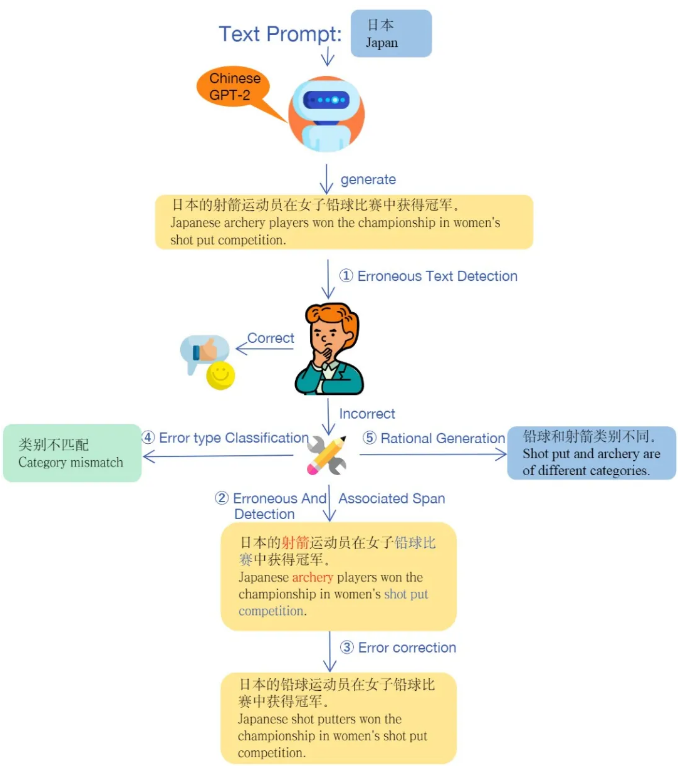
TGError: An Error-Annotated Dataset and Benchmark Tasks for Text Generation from Pretrained Language Models
为了对语言模型的性能进行评估,我们构建了 TGError,一个由模型生成文本并由人工标注的数据集,并在数据集上设置了多个任务。与同类工作相比,该数据集的文本由模型生成,因此它更能暴露出模型的问题,并能避免人工编写带来的人为影响。我们用经过挑选的引导词来使 NEZHA-Gen 模型生成句子,这些句子中可能会包含一些错误,识别、纠正这些模型“无意间”生成的错误对当前的语言模型来说难度非常高。这些句子由经过训练的众包来进行标注,具体来说,我们首先标注一个句子是否包含错误,如果包含,则需要进一步标注错误的类型、错误的位置、错误的关联位置、错误的修正和错误的原因解释。这些标注内容作为下游任务用来评估语言模型的性能。我们在论文中发布了了包含4万7千条样本的数据集,更大规模的标注仍在进行中。这是第一个由模型生成句子的、开放领域的数据集,我们的基线实验也表明,当前的主流语言模型在处理我们的任务时性能远低于同类任务,说明语言模型仍具有很大的提升空间,因此该数据集可以作为一种评估方式指导语言模型未来的发展。
机器翻译
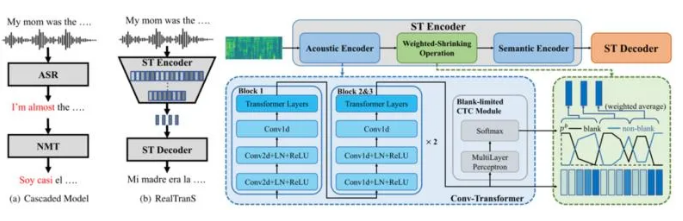
RealTranS: End-to-End Simultaneous Speech Translation with Convolutional Weighted-Shrinking Transformer
端到端实时语音翻译是一种直接将一种语言的语音实时翻译成另一种语言的文本的技术。它在许多场景如国际会议的同步翻译、实时视频的自动字幕等中都可使用。对比目前比较广泛使用的级联模型(即基于实时语音识别的结果再做机器翻译),端到端的模型有延迟低、模型小、避免错误传递等优势。然而目前大部分端到端的语音翻译模型都是基于非实时场景设计的,在实时场景下可能无法适用。在本工作中,我们提出了RealTranS,一个针对实时语音翻译的端到端模型。为了弥合语音和文本之间的模态差异,RealTranS使用交错卷积和单向transformer层来逐步下采样输入的语音序列,并进行声学建模,然后使用加权收缩(weighted-shrinking)操作和语义编码器将语音特征映射到文本空间。此外,为了提高实时场景下的模型性能,我们提出了一个空白惩罚(blank penalty)机制来增强收缩质量,并提出了一个Wait-K-Stride-N的实时策略来进行实时解码期间的本地重排序(local reranking)。实验表明,采用Wait-K-Stride-N策略的RealTranS在不同延迟设置下的性能均优于先前的端到端模型以及级联模型。
Two Parents,One Child: Dual Transfer for Low-Resource Neural Machine Translation
当平行语料规模较小时,神经机器翻译的质量会明显下降。迁移学习可以用来辅助低资源机器翻译的训练,但以往的工作一般只利用高资源平行语料或单语语料进行辅助。本文提出的方法可以同时利用多种辅助数据进行迁移,包括高资源平行语料和单语语料。前者蕴含的知识由高资源翻译模型捕捉,后者蕴含的知识由预训练语言模型捕捉,随后本文方法将两者同时迁移至低资源翻译模型。实验表明,本文方法在多个翻译方向上均表现出良好的效果,即便低资源平行语料规模很小仍能取得可观的翻译质量。此外,本文方法能够在反译的基础上进一步提升,因此具有较高的实用价值。
预训练理论
Improved OOD Generalization via Adversarial Training and Pre-training
如何训练在样本外(OOD)数据上具有良好泛化性的模型这一问题在机器学习领域被广泛关注。在本文中,我们基于Wasserstein距离定义了样本外泛化性,同时证明了输入更鲁棒的模型在样本外数据上泛化性更好。考虑到已有研究表明:对抗训练能够提升模型的输入鲁棒性,我们理论上证明了对抗训练后的模型在样本外数据上剩余误差(excess risk)的收敛性。该结论在图像数据和文本数据上同时被验证。除此之外,在预训练-微调的框架下,我们证明了对抗预训练得到的模型具有更强的输入鲁棒性。因此,对抗预训练能够给下游任务提供一个具有更好样本外泛化性的起始点。
完整论文列表:
Efficient Pretrained Models
·BinaryBERT: Pushing the Limit of BERT Quantization. In ACL 2021.
·AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pretrained Language Models. In ACL 2021.
·GhostBERT: Generate More Features with Cheap Operations for BERT. In ACL 2021.
·SparseBERT: Rethinking the Importance Analysis in Self-attention. In
·MATE-KD: Masked Adversarial TExt, a Companion to Knowledge Distillation. In ACL 2021.
Analysis and Evaluation of NLP Models
·TGError: An Error-Annotated Dataset and Benchmark Tasks for Text Generation from Pretrained Language Models. In ACL 2021.
·Exploring Discourse Structures for Argument Impact Classification. In ACL 2021.
Machine Translation and Multilinguality
·RealTranS: End-to-End Simultaneous Speech Translation with Convolutional Weighted-Shrinking Transformer. In Findings of ACL 2021.
·Two Parents, One Child: Dual Transfer for Low-Resource Neural Machine Translation. In Findings of ACL 2021.
·XeroAlign: Zero-shot Cross-lingual Transformer Alignment. In Findings of ACL 2021.
·Generalising Multilingual Concept-to-Text NLG with Language Agnostic Delexicalisation. In ACL 2021.
·Multi-Head Highly Parallelized LSTM Decoder for Neural Machine Translation. In ACL 2021.
Dialogue and Question Answering
·A Mutual Information Maximization Approach for the Spurious Solution Problem in Weakly Supervised Question Answering. In ACL 2021.
·Dialog TAHOE: End-to-End Task-Oriented Modeling with Hybrid Knowledge Management. In Findings of ACL 2021.
Machine Learning for NLP models
·Improved OOD Generalization via Adversarial Training and Pretraing. In ICML 2021.
·Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. ICML 2021.
·Not Far Away, Not So Close: Sample Efficient Nearest Neighbour Data Augmentation via MiniMax. In Findings of ACL 2021.
·Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger. In ACL 2021.
·Better Robustness by More Coverage: Adversarial and Mixup Data Augmentation for Robust Finetuning. In Findings of ACL 2021.
·Enhancing Transformers with Gradient Boosted Decision Trees for NLI Fine-Tuning. In Findings of ACL 2021.
·LV-BERT: Exploiting Layer Variety for BERT. In Findings of ACL 2021.
·End-to-End Self-Debiasing Framework for Robust NLU Training. In Findings of ACL 2021 (short).
·Quotation Recommendation and Interpretation Based on Transformation from Queries to Quotations. In ACL 2021 (Short).
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢