
【论文标题】Using Self-Supervised Co-Training to Improve Facial Representation
【作者团队】Mahdi Pourmirzaei, Farzaneh Esmaili, Gholam Ali Montazer
【发表时间】2021/05/13
【机 构】塔比亚特·莫达雷斯大学,伊朗
【论文链接】https://arxiv.org/ftp/arxiv/papers/2105/2105.06421.pdf
【推荐理由】本文出自伊朗,塔比亚特·莫达雷斯大学,研究提出了一种用于标准监督学习(SL)的框架,称为混合学习(HL),以多任务学习(MTL)的方式使用了与SL进行自监督的协同训练,最终帮助监督头(SH)在相同的训练环境中降低不同扩充和低数据方案下的错误率。
在本文中,首先,在不同增强水平下测试了ImageNet预训练对面部表情识别(FER)的影响。从结果可以看出,与ImageNet微调相比,从头开始训练可以达到更好的性能,而增强级别更高。此后,提出了一种用于标准监督学习(SL)的框架,称为混合学习(HL),该框架以多任务学习(MTL)的方式使用了与SL进行自我监督的协同训练。利用自监督学习(SSL)可以从输入数据中获取其他信息,例如来自面孔的空间信息,这些信息可以帮助完成主要的SL任务。研究了这种方法如何用于具有自我监督的预任务(例如拼图和涂装)的FER问题。这两种方法可以帮助监督头(SH)在相同的训练环境中降低不同扩充和低数据方案下的错误率。通过两种完全不同的HL方法在AffectNet上获得了最新技术,而无需利用其他数据集。此外,HL在两个与面部相关的不同问题上的作用得到了证明,分别是头部姿势估计和性别识别,得出的结论是错误率分别降低了9%和1%。此外,HL方法阻止了模型的过度拟合。
下图为标准监督学习和自监督学习结合框架图,训练分为两个阶段。 首先,在预定义的增强下从头开始训练骨干。 然后,在第二阶段中,在与第一阶段相同的设置下,另一个骨干列车将带有一个额外的解码器头。解码器创建重建的图像,该图像提供给在第一阶段中创建的离线主干。 最后,两个图像的表示应尽可能相似。从另一个角度来看,经过预训练的EfficientNet网络可以假定为教师,而EfficientNet为学生。
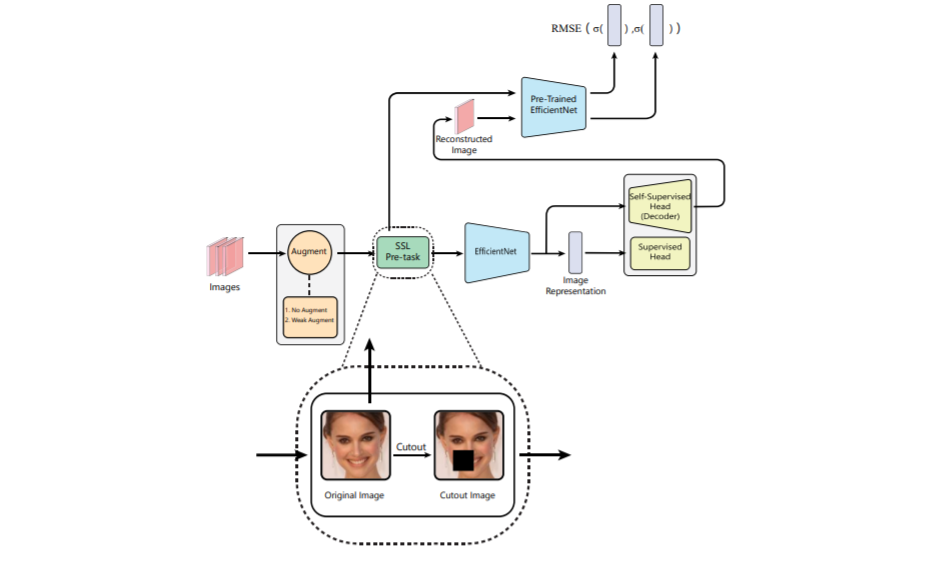
图1 标准监督学习和自监督学习结合框架图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢