
【论文标题】High-Resolution Complex Scene Synthesis with Transformers
【作者团队】Manuel Jahn, Robin Rombach, Björn Ommer
【发表时间】2021/05/13
【机构】海德堡大学
【论文链接】https://arxiv.org/pdf/2105.06458.pdf
本文出自海德堡大学,作者提出了一种基于纯似然训练的高分辨率复杂场景合成 Transformer 模型,无需使用辅助损失和掩模生成器等工程化手段即可实现在 COCO- stuff 和 Visual Genome 数据集上最佳的性能。
最近,利用粗粒度布局通过深度生成模型对复杂场景图像进行可控合成得到了广泛的应用。然而,目前的研究结果仍然没有达到高分辨率合成的预期。本文作者假设,这主要是由于这些方法高度工程化的本质,它们通常依赖于辅助损失和掩模生成器等中间步骤。
在本文中,作者提出了一个正交的方法来完成该任务,其中生成模型以没有额外目标函数的纯似然训练为基础。为此,作者首先使用对抗训练优化强大的压缩模型,该模型通过离散的潜在瓶颈来学习如何重建输入,从而有效地剥离高频细节(如纹理)的潜在表征。随后,作者训练了一个自回归 Transformer 模型来学习离散的图像表征分布,该分布以布局的词例化(tokenized)版本为条件。
实验结果表明,本文提出的系统能够合成与给定布局一致的高质量图像,该系统在 COCO- stuff 和 Visual Genome 上取得了目前最佳的 FID 分数。
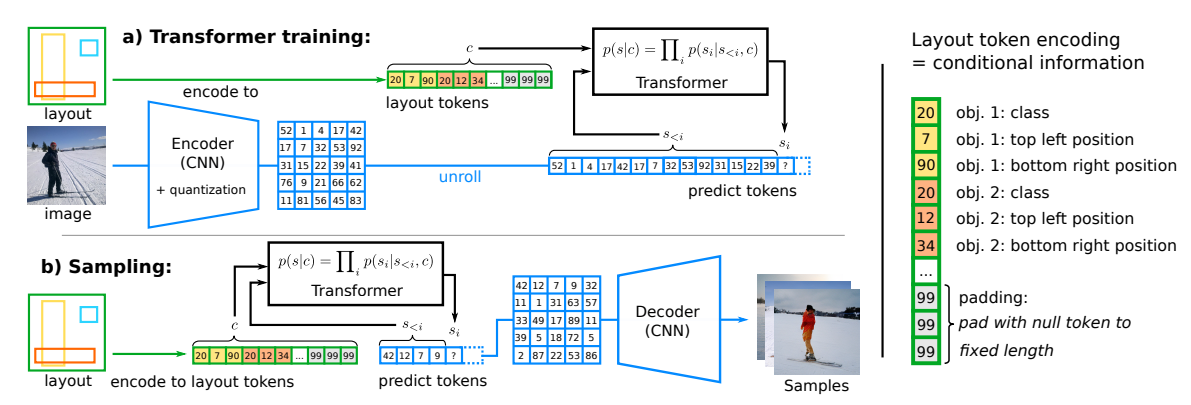
图 1:本文提出的方法
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢