脏数据可以说是所有AI从业者、数据分析师、数据科学家的噩梦。麻省理工学院的研究人员最近带来了一种全新的系统PClean,能够自动地清洗脏数据,如错误、值缺失、拼写错误和值不一致,并且还能够根据概率统计出常识知识来推断信息。
论文名称:PClean: Bayesian Data Cleaning at Scale with Domain-Specific Probabilistic Programming
这个名为 PClean 的系统是概率计算项目(Probabilistic Computing Project)研究人员编写的针对特定领域的概率编程语言,旨在简化人工智能应用程序的开发并实现自动化,例如时间序列和数据库进行建模)。
根据Anaconda和Figure Eight所做的调查,清洗数据可能会占用数据科学家四分之一的时间。如何将这个任务自动化,一直以来都是一个具有挑战性的任务。因为不同的数据集需要不同类型、不同层次的清理,而且清晰过程经常需要依赖常识来对世界上的物体进行判断,例如一个城市表中,需要判断哪些值不属于这列。
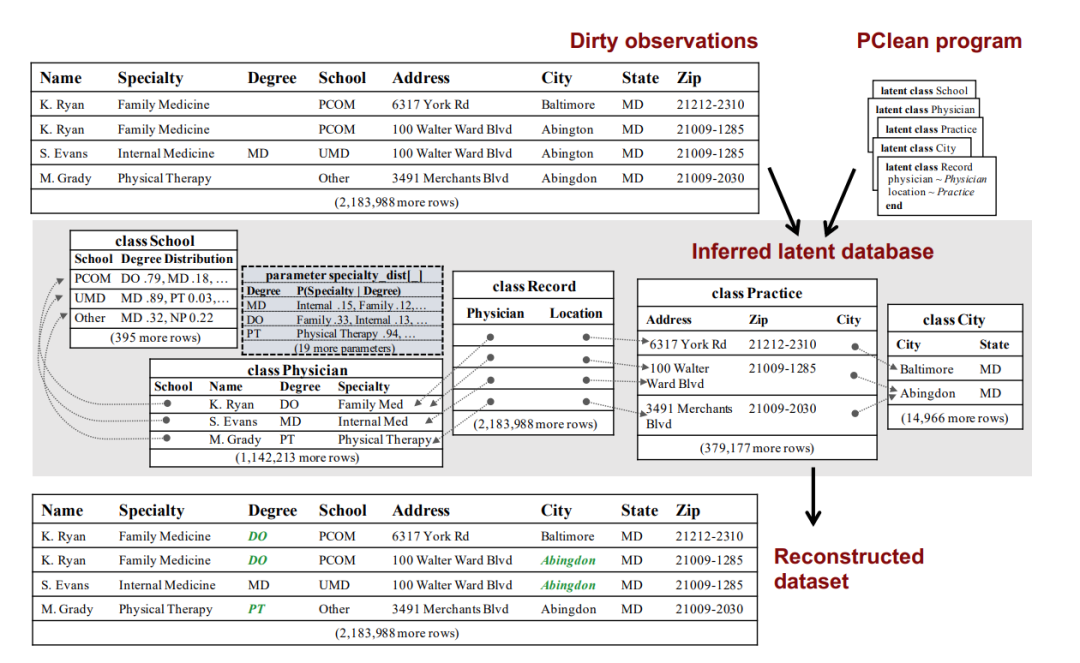
PClean 为这类判断提供了一个通用的常识模型,可以根据特定的数据库和错误类型进行定制化操作。PClean 使用基于知识的方法来自动化数据清洗的过程: 即用户在定义数据的时候,已经隐含包括了数据库的背景知识以及可能出现的各种问题。
用户可以向 PClean 提供有关域以及数据可能如何损坏的背景知识。PClean 通过常识性概率推理将这些知识结合起来得出答案。例如,如果对租金类的常识有更多的了解,PClean 就能推断正确的比弗利山是在加利福尼亚,因为被调查者居住的地方的租金成本很高。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢