
【论文标题】Stacked Acoustic-and-Textual Encoding: Integrating the Pre-trained Models into Speech Translation Encoders
【论文链接】https://arxiv.org/abs/2105.05752
【作者团队】Chen Xu , Bojie Hu , Yanyang Li , Yuhao Zhang , Shen Huang , Qi Ju2 , Tong Xiao, Jingbo Zhu
【发表时间】2021.5.12
【推荐理由】论文收录于ACL-2021会议,研究人员提出了一种用于语音翻译堆叠声学和文本的编码方法,它在前期按照自动语音识别编码器处理声学序列,但在后期按照机器翻译编码器处理全局表示,这种方法能很好的将预训练模型纳入到系统中。除此之外,研究人员还开发了一个适配器模块来缓解预训练的自动语音识别编码器和机器翻译编码器之间的表示不一致,以及一个多教师知识提炼方法来保留预训练的知识。
鉴于语音翻译数据稀缺,编码器预训练在端到端的语音翻译中很有前途。但语音翻译编码器不是自动语音识别或机器翻译编码器的简单实例。例如,研究人员发现自动语言识别编码器缺乏全局语境表示,但这是翻译所必需的;而机器翻译编码器的设计不是为了处理长的而是局部关注的声学序列。在LibriSpeech En-Fr和MuST-C En-De数据集上的实验结果表明,论文的方法在BLEU得分上达到了18.3和25.2的最先进性能。根据当前的研究可知,该论文是第一个开发出端到端的语音翻译系统,在有大规模自动语音识别和机器翻译数据的情况下,可以达到与级联语音翻译对应相当的甚至更好的BLEU性能。
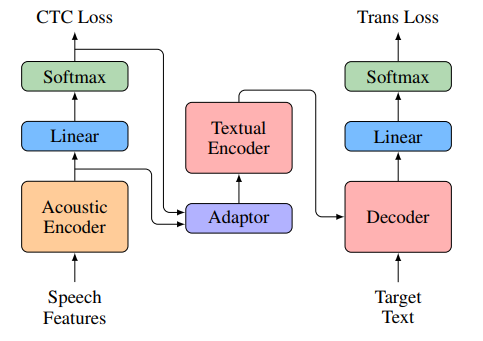
图:堆叠声学和文本编码器的结构图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢