【论文标题】BertGCN: Transductive Text Classification by Combining GCN and BERT
【作者团队】Yuxiao Lin, Yuxian Meng, Xiaofei Sun, Qinghong Han, Kun Kuang, Jiwei Li, Fei Wu
【发表时间】2021/05/16
【机 构】浙大
【论文链接】https://arxiv.org/abs/2105.05727v1
【代码地址】https://github.com/ZeroRin/BertGCN
【推荐理由】结合BERT和GNN的优点
在这项工作中,作者提出了BertGCN,一个结合大规模预训练和直推学习的文本分类模型。BertGCN在语料库数据集上构建了一个异质图,并使用文档的BERT表征作为节点。通过在BertGCN中联合训练BERT和GCN模块,所提出的模型能够利用两个领域的优势:利用了大量的原始数据的大规模的预训练;直推学习,它通过图卷积传播标签影响,为训练集数据和未标记的测试数据联合学习表征。实验表明,BertGCN在广泛的文本分类数据集上实现了SOTA性能。
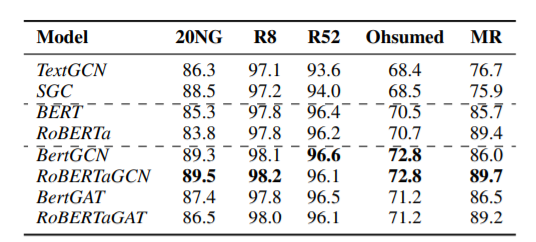
由上图可以看到,BertGCN和RoBERTaGCN在所有数据集中表现最好。只使用BERT和RoBERTa通常比GCN变种效果要好,这是由于大规模预训练带来的好处。与BERT和RoBERTa相比,BertGCN和RoBERTa的性能提升在20NG和Ohsumed数据集上的性能提升非常明显,这是因为20NG和Ohsumed中的文本平均长度的平均长度比其他数据集长得多。图结构是用单词-文档所构建的,这意味着长文本可能会产生更多通过中间词节点所传输的文档连接。当与GCN结合时这可能有利于通过图的信息传递并导致更好的性能,这也可以解释为什么GCN模型在20NG上比BERT模型表现更好。对于文本长度较少的数据集,如R52和MR,图结构的力量是有限的,因此相对于20NG来说,性能提升较小。BertGAT 和RoBERTaGAT也能从图结构中受益,由于缺乏边权重信息,它们的性能不如GCN变体。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢