
最近,预训练的语言模型在许多NLP任务中表现出卓越的性能。然而,他们的社会性智能,即需要对他人的当前情况和心理状态进行常识性推理,仍在发展之中。为了提高语言模型的社会性智能,我们专注于社会IQA数据集,一个需要社会和情感常识推理的任务。在预训练的RoBERTa和GPT2模型的基础上,作者提出了一些架构变化和扩展,以及利用外部常识语料以优化社会IQA的模型。本文提出的系统取得了与排行榜上那些排名靠前的模型相比得到了具有竞争力的结果。这项工作证明了预训练语言模型的优势,并提供了改善其在特定任务中表现的可行方法。
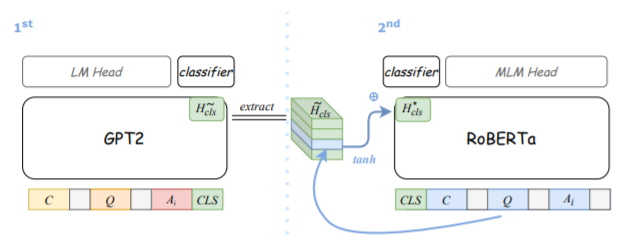
上图为本文使用的二段式架构。作者预计GPT2和RoBERTa可能是互补的。为了有效地融合这两个模型,作者没有对它们进行训练因为它的计算成本很高;相反,通过一个二段式架构,在每个步骤中只需要在内存中保留一个预训练的模型。首先,再社会IQA数据集上对GPT2模型进行微调,将[CLS]标记放在C、Q和Ai(背景,问题,回答)的串联序列的最后,并将MLP分类器堆叠在上面。作者认为[CLS]的最终隐藏表示浓缩了整个序列的一些语义,它在微调后为这个多选任务提供了有用的信息。因此,本文提取[CLS]标记表示,并在继续微调RoBERTa(第二步)时将其作为一个额外的特征。本文提出的2步合集方法特别适合于大型预训练模型,同时与传统的Stacked泛化法有类似的想法。
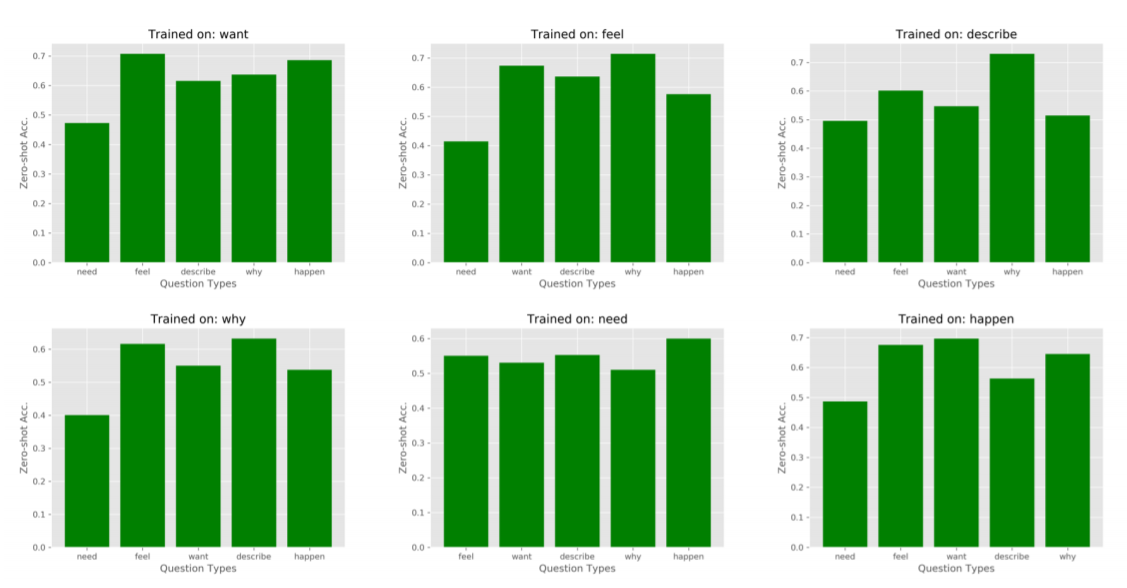
上图为zero-shot问题类型迁移的结果。作者根据训练实例的不同问题类型对模型进行了微调,只对一种类型进行了调整,并对其他类型进行了评估。这种设置挑战了模型进行零散的问题类型转移的能力。图中的结果显示,大多数的结果比随机猜测要好得多(33%),尽管有些类型诸如 "为什么"、"需要"、"发生 "等类型,在训练中所占的比例不到15%。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢