
论文标题:Vision Transformer for Fast and Efficient Scene Text Recognition
论文链接:https://arxiv.org/abs/2105.08582
代码链接:https://github.com/roatienza/deep-text-recognition-benchmark
作者单位:菲律宾大学
又好又快!简单的单阶段模型,强调准确率、速度和计算的综合平衡,性能优于TRBA、Rosetta等网络,代码现已开源!
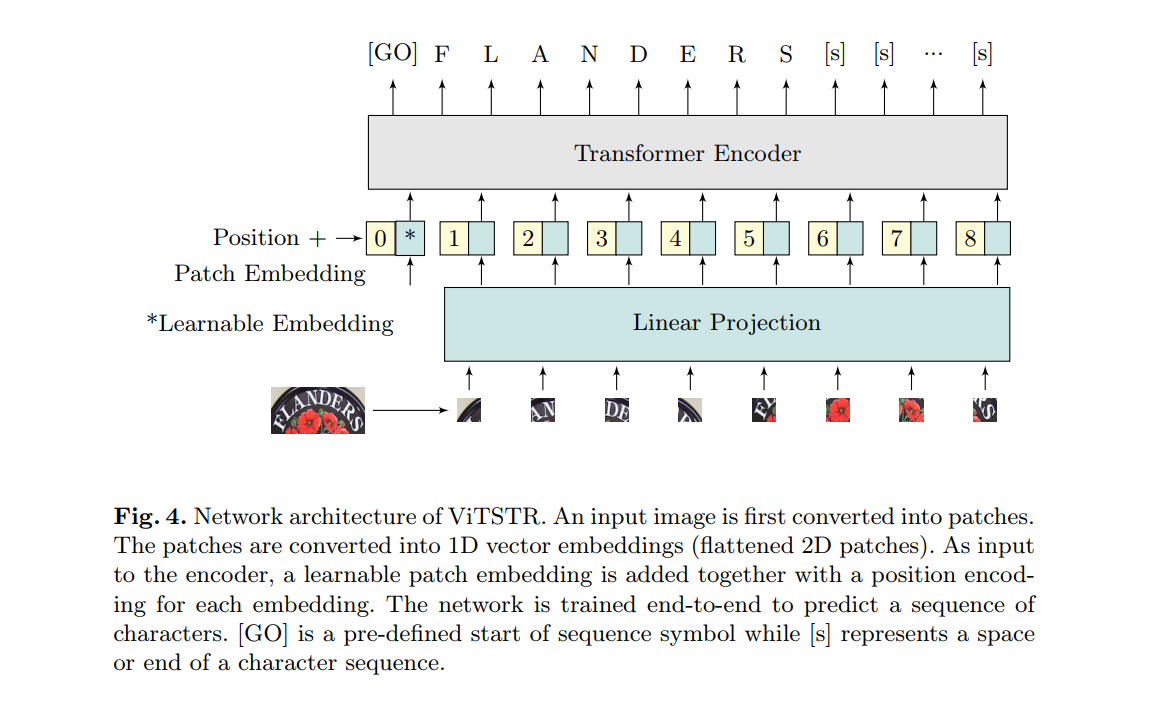
场景文本识别(STR)使计算机能够在自然场景中读取文本,例如物体标签,道路标志和指示。STR帮助机器执行明智的决策,例如要拾取的对象,前进的方向以及下一步的操作。在STR的工作主体中,始终将重点放在识别准确性上。很少强调速度和计算效率,这对于能源受限的移动机器尤其重要。在本文中,我们提出了ViTSTR,这是一种具有简单单阶段模型架构的STR,该架构基于计算和参数有效的视觉Transformer(ViT)。在可比的强基线方法(如TRBA,准确度为84.3%)上,我们的小型ViTSTR仅使用43.4%的参数数量和42.2%的速度就可以达到2.4%的竞争准确度(82.6%(数据增强时为84.2%))。快艇。 ViTSTR的微型版本以2.5倍的速度实现了80.3%的精度(数据增强时为82.1%),仅要求参数数量的10.9%和FLOPS 11.9%。通过数据增强,我们的基本ViTSTR的准确率达到85.2%(不进行增强时为83.7%),而TRBA的速度为2.3倍,但需要更多的参数73.2%和FLOPS的61.5%。在权衡方面,几乎所有ViTSTR配置都处于边界或边界附近,以同时最大化准确性,速度和计算效率。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢