
【论文标题】VTNET: VISUAL TRANSFORMER NETWORK FOR OBJECT GOAL NAVIGATION
【作者团队】Heming Du , Xin Yu, Liang Zheng
【机构】 澳洲国立大学;悉尼科技大学
【发表时间】2021/5/21
【论文链接】https://arxiv.org/pdf/2105.09447.pdf
【推荐理由】
本文面向目标导航任务中,确定导航动作时,如何对观察到的场景进行有效的视觉表示的问题,提出了:用于目标导航的Transformer网络(VTNET),主要目的在于学习导航中的信息视觉表示。
VTNet包含视觉表示的两个关键属性:首先,利用场景中所有对象实例之间的关系;其次,强调对象和图像区域的空间位置,以便可以学习定向导航信号。此外,作者还开发了一种预训练方案,将视觉表示与导航信号相关联,促进导航策略的学习。
VTNet的结构示意图如图1所示,将对象和区域要素及其位置线索嵌入为空间感知描述符,然后通过注意力操作合并所有编码的描述符,以实现信息的导航表示,进而使得智能体能够探索视觉观察与导航动作之间的相关性。
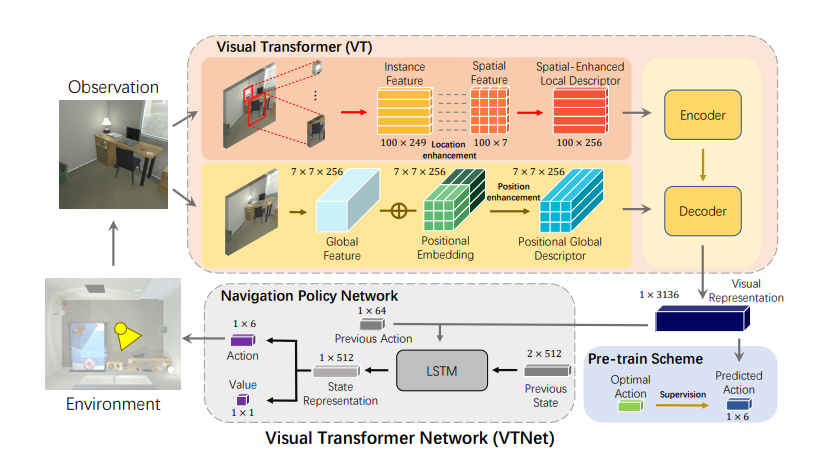
图1: VTNET结构示意图
在实验环节中,VTNet在AI2-Thor人工环境中进行了实验,结果表明VTNet在看不见的测试环境中明显优于现有的最新方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢