
标题:谷歌|KELM: Integrating Knowledge Graphs with Language Model Pre-training Corpora(KELM:将知识图与语言模型预训练语料库集成)
大型预训练自然语言处理(NLP)模型,例如BERT,RoBERTa,GPT-3,T5和REALM,利用了从Web派生并针对特定任务数据进行微调的自然语言语料库,并在各种NLP任务中取得了重大进展。但是,自然语言文本仅代表了有限的知识范围,事实可能以多种不同方式包含在单词句中。此外,文本中存在非事实信息和有害成分最终可能会导致结果模型产生偏差。
替代的信息来源是知识图(KGs),它由结构化数据组成。 KG本质上是事实的,因为信息通常是从更受信任的来源中提取的,并且后期处理过滤器和人工编辑者可以确保删除不适当和不正确的内容。因此,可以合并它们的模型具有提高事实准确性和降低伤害性的优点。但是,它们的不同结构格式使得很难将它们与语言模型中的现有预训练语料库进行集成。
在NAACL 2021接受的“用于知识增强的语言模型预训练的基于知识图的合成语料库生成”(KELM)中,我们探索了将KG转换为合成自然语言句子以增强现有的预训练语料库,从而将其集成到预训练语料库中的能力。 在不进行架构更改的情况下训练语言模型。为此,我们利用可公开获得的英文Wikidata KG并将其转换为自然语言文本,以创建合成语料库。然后,我们使用合成语料库扩充REALM(一种基于检索的语言模型),作为在预训练中整合自然语言语料库和KG的一种方法。我们已为更广泛的研究社区公开发布了该语料库。
将KG转换为自然语言文本
KG由以结构化格式明确表示的事实信息组成,通常以[主题实体,关系,对象实体]三元组的形式显示,例如[10x10写真集,初始,2012年]。一组相关的三元组称为实体子图。基于三元组的先前示例的实体子图的示例为{[10x10相册,非营利组织的实例],[10x10相册,初始,2012年]},如下图所示。 KG可以看作是互连的实体子图。
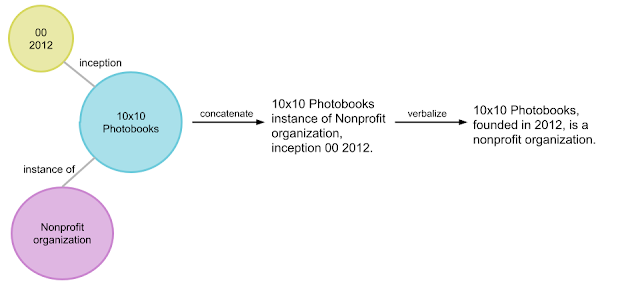
图1
将子图转换为自然语言文本是NLP中的一项标准任务,称为数据到文本生成。尽管在基准数据集(例如WebNLG)的数据到文本生成方面已经取得了重大进展,但是将整个KG转换为自然文本仍然存在其他挑战。大型KG中的实体和关系比小型基准数据集更为广泛和多样。此外,基准数据集由预定义的子图组成,这些子图可以形成流利的有意义的句子。对于整个KG,还需要创建这样的对实体子图的分割。
为了将Wikidata KG转换为合成的自然句子,我们开发了一个名为“来自KG的文本生成器”(TEKGEN)的语言化管道,该管道由以下组件组成:启发式对齐的Wikipedia文本和Wikidata KG三元组的大型训练语料库 ,将KG三元组转换为文本的文本到文本生成器(T5),实体子图创建器,用于生成将要被口头表达的三元组组,最后是用于去除低质量输出的后处理过滤器。 结果是一个包含整个Wikidata KG作为自然文本的语料库,我们将其称为知识增强语言模型(KELM)语料库。 它由约1800万个句子组成,跨越约4500万个三元组和1500个关系。

图2
集成知识图和自然文本进行语言模型预训练
我们的评估表明,KG语言化是将KG与自然语言文本集成的有效方法。 我们通过增强REALM的检索语料库来证明这一点,REALM的检索语料库仅包含Wikipedia文本。
为了评估语言化的有效性,我们使用KELM语料库(即“语言化三元组”)增强了REALM检索语料库,并将其性能与不带语言化的串联三元组的增强效果进行了比较。 我们使用两种常见的开放域问答数据集:自然问题和网络问题,使用每种数据增强技术来测量准确性。
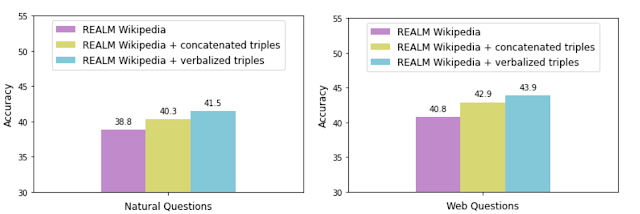
图3
甚至连连的三元组都增强REALM可以提高准确性,从而有可能添加显式或根本不以文本形式表示的信息。但是,用三重言语表示法进行增强可以使KG与自然语言文本语料库更平滑地集成,如更高的准确性所证明的。我们还在称为LAMA的知识探针上观察到了相同的趋势,该知识探针使用空白问题来查询模型。
结论
借助KELM,我们提供了一个公开的KG语料库,作为自然文本。我们表明,KG言语化可用于将KG与自然文本语料库相集成,以克服其结构差异。它具有用于知识密集型任务(例如问题解答)的实际应用程序,在这些应用程序中,必须提供事实知识。而且,这样的语料库可以应用于大型语言模型的预训练,并且可以潜在地减少有害性并改善事实性。我们希望这项工作能够鼓励在将结构化知识源集成到大型语言模型的预训练中取得更大的进步。
论文下载:https://arxiv.org/pdf/2010.12688
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢