
【论文标题】DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
【作者团队】Dawn Drain, Colin B. Clement, Guillermo Serrato, Neel Sundaresan
【发表时间】2021/05/19
【机 构】Microsoft Cloud and AI
【论文链接】https://arxiv.org/pdf/2105.09352v1.pdf
【推荐理由】预训练模型实际应用
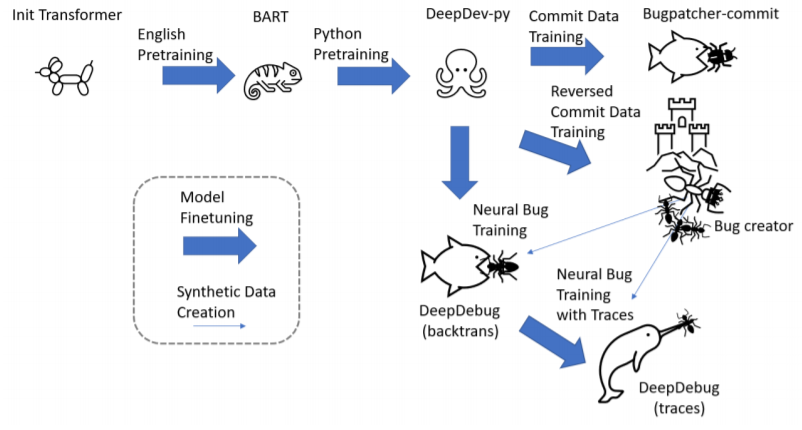
在软件开发过程中,bug定位和程序修复的联合任务是一个重要组成部分。本文提出了DeepDebug,一种使用大型预训练transformer进行自动debug的方法。本文首先在提交数据上训练一个错误生成模型以生成合成bug。我们将这些合成bug模型应用于两个目的。首先,作者直接在200K仓库的所有函数上训练一个回译模型。接下来,作者专注于可以执行测试的10K仓库,并为这些仓库中所有通过测试的函数创建buggy版本。这些为本文工作提供了丰富的调试信息,如堆栈痕迹和打印语句,其被用来微调我们的预训练模型。最后,我们通过将上下文窗口扩展到有问题的函数本身之外,并按优先顺序排列添加一个由该函数的父类、导入、签名、文件字符串和方法体组成的骨架来加强我们所有的模型。在QuixBugs基准测试中,我们发现的修复总数增加了50%以上,同时也将假阳性率从35%降低到5%,并将超时时间从6小时降低到1分钟。在我们自己的可执行测试基准中,我们的模型在不使用跟踪的情况下,第一次尝试就修复了68%的错误,而在添加跟踪后,第一次尝试就修复了75%的错误。作者将开源他们的框架和验证集,以便在可执行测试中进行评估。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢