
【论文标题】Pay Attention to MLPs
【作者团队】Hanxiao Liu, Zihang Dai, David R. So, Quoc V. Le
【发表时间】2021/05/17
【机 构】Google Research, Brain Team
【论文链接】https://arxiv.org/pdf/2105.08050v1.pdf
【推荐理由】MLP浪潮新hot作,相关作品中的佼佼者
Transformer已经成为深度学习中最重要的架构创新之一,并在过去几年中实现了许多突破。在这里,作者提出了一个简单的无注意力网络架构--gMLP。它完全基于带有门控的MLP,并在关键的语言和视觉应用中表现的和Transformer一样表现出色。本文的比较表明,自注意力对于视觉Transformer来说并不关键,因为gMLP可以实现同样的准确性。对于BERT,本文的模型在预训练的perplexity上与Transformers持平,并且在一些下游任务上表现更好。在gMLP表现较差的微调任务上,使gMLP模型大幅增大可以缩小与Transformers的差距。总的来说,本文的实验表明,在数据和计算量增加的情况下,gMLP可以和Transformers一样延申扩展。
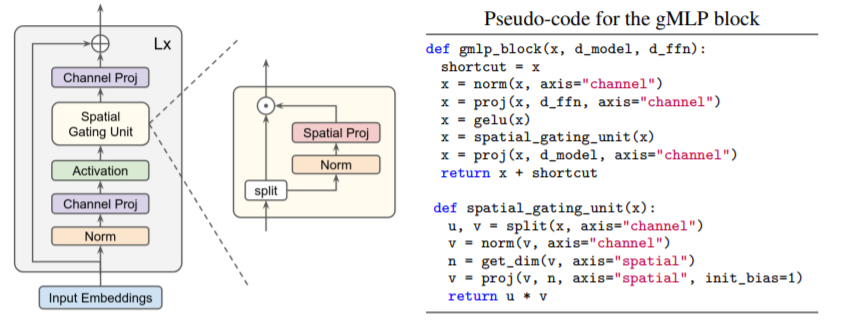
每个block设计如上图所示,架构为L个gMLP block 堆叠起来。关键操作是SGU的输入和Spatial Proj的输出做乘积以起到门控的效果。
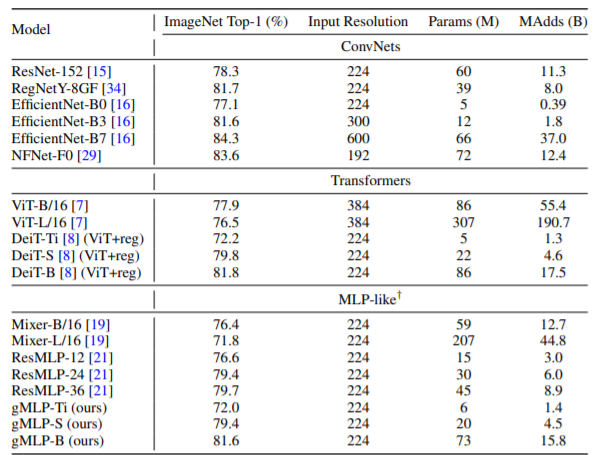
ImageNet上的结果如上,MLP-like的结果媲美transformer。。。。。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢