
【论文标题】True Few-Shot Learning with Language Models
【作者团队】Ethan Perez, Douwe Kiela, Kyunghyun Cho
【发表时间】2021/05/24
【机 构】NYU,脸书
【论文链接】https://arxiv.org/pdf/2105.08928v1.pdf
【代码链接】https://github.com/ethanjperez/true_few_shot
【推荐理由】小样本学习的深度分析
预训练语言模型(LMs)即使在从小样本中学习,依旧在许多任务中表现良好。但先前的工作使用许多保留的实例来调整学习的各个方面,如超参数、训练目标和自然语言模板("prompts")。本文评估了当这种保留的实例不可用时,LMs的小样本能力,即真正的小样本学习。作者测试了两种模型选择标准,交叉验证和最小描述长度,用于在真正的小样本学习环境中选择LM的prompt和超参数。平均来说,这两种方法都略微优于随机选择,而大大低于基于保留实例的选择。此外,选择标准往往倾向于选择那些表现明显比随机选择的模型差的模型。即使考虑到我们在选择过程中对模型真实性能的不确定性,我们也发现类似的结果。总的来说,我们的研究结果表明,考虑到小样本模型选择的难度,之前的工作明显高估了LM的真实小样本能力。
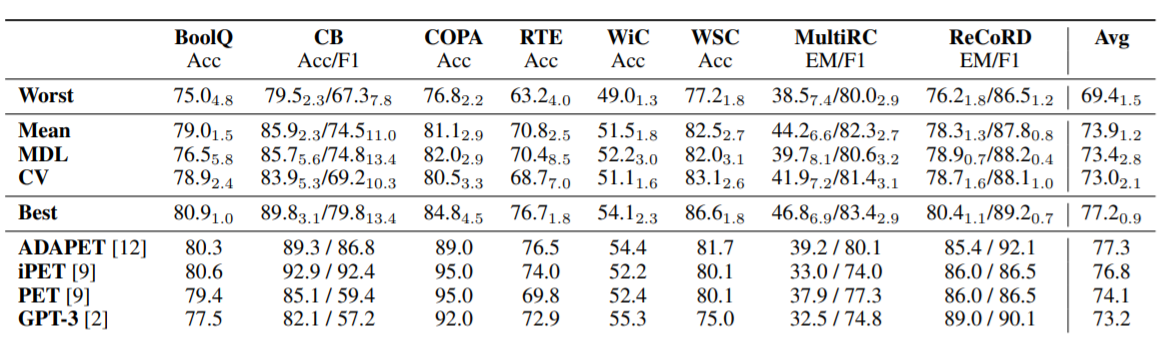
上表展示了当通过CV/MDL(交叉验证和最小描述长度)选择early stopping和LM掩蔽时,ADAPET对SuperGLUE验证的结果,以及验证时选择的最差/平均/最好的超参数相比ADAPET的结果。(四个32-shot训练集的平均偏差)。在所有的任务中,CV/MDL选择的超参数的表现与平均水平相似或更差,并比最佳超参数低几个点。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢