
简介:机器学习领域领三大最具影响力会议之一的ICML(International Conference on Machine Learning) 机器学习国际会议公布录用结果,华为诺亚方舟实验室决策推理方向6篇论文被接收,其中包括一篇长文大会口头报告(LongOral)。研究涉及图卷积网络、神经网络、博弈论、强化学习等多个领域的探索。本文将分别概述研究成果与亮点。
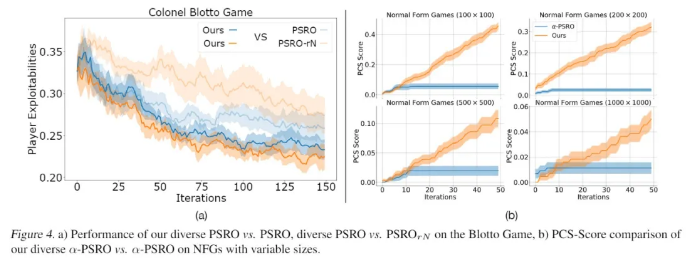
促进行为多样性对于解决具有非传递性的动态博弈至关重要,因为这些博弈的策略存在周期性,而且没有一致的赢家(例如,剪刀石头布)。然而,在定义多样性和构建具有多样性意识的学习动态方面缺乏严格的处理。这项工作提供了游戏中行为多样性的几何解释,并引入了一种基于决定点过程(DPP)的新的多样性度量。通过将多样性度量纳入最佳响应动态,我们开发了多样化的策略空间响应机制,用于解决正常形式的博弈和开放式博弈。我们证明了不同最佳响应的唯一性和我们算法在两人博弈上的收敛性。重要的是,我们证明了最大化基于DPP的多样性度量保证了扩大由代理策略混合跨越的凸多面体。为了验证我们的多样性感知求解器,我们在数十个显示出强非传递性的博弈上进行了测试。结果表明,通过找到有效和多样化的策略,可以实现比最先进的求解器更低的可利用性。
Learning in Nonzero-Sum Stochastic Games with Potentials
多智能体强化学习(MARL)在解决离散合作博弈场景方面已变得非常有效。然而,MARL还没有渗透到团队和零和博弈建模的设置之外,将其限制在一小部分多智体系统中。这项工作介绍新一代MARL学习器,它可以处理非零和收益的结构和连续设置。尤其是,我们在具有连续状态动作空间的一类称为随机潜在博弈(SPG)的博弈中研究了MARL问题。与所有代理享有共同的奖励的合作游戏不同,SPG能够模拟代理寻求实现其个人目标的现实场景。从理论上证明了我们的学习方法SPot-AC使能够在多项式时间内学习Nash均衡策略。
Lipschitz Normalization forSelf-Attention Layers with Application to Graph Neural Networks

基于注意力的神经网络在许多应用中都达到最优的效果。然而当层数增加时,它们的性能趋于下降。在这项研究工作中,我们发现通过标准化注意力得分来加强Lipschitz连续性,可以显着改善深度注意力模型的性能。首先,我们的发现深度图注意力网络(GAT)在训练过程中会出现梯度爆炸问题,从而导致基于梯度的训练算法的性能表现较差。为解决该问题,我们分析了注意力模块的Lipschitz连续性,据此引入了LipschitzNorm算子。自在注意力机制中,LipschitzNorm是一种的简单高效的非参数归一化方法,可以确保模型的Lipschitz连续性。我们将LipschitzNorm应用于GAT和GraphTransformers,发现深度图模型(10到30层)的性能得到了显着提高。我们的实验显示,当节点间存在远程交互时,使用LipschitzNorm的深层GAT模型在节点标签预测任务中达到了当前最高水平。此外,在基准节点分类任务中,我们的方案也显示了与未归类的同类算法一致的提升效果。
Best Arm Identification in Graphical Bilinear Bandits

我们引入了一个新的基于图的双线性bandit问题,由学习器(或中心实体)将arms分配到图的节点,并观察每条边的噪声的双线性奖励,该奖励表示了两个节点之间的交互信息。我们研究了最佳arms识别问题,其中学习器希望找到最大化双线性奖励总和的图分配。通过有效利用这个bandit问题的几何学特性和随机采样理论保证下,我们提出了一种去中心化的分配策略。此外,我们分析了不同图结构(例如星形,完整或圆形)对收敛速度的影响,并通过实验验证了该依赖性。
RNN with Particle Flow for Probabilistic Spatio-temporal Forecasting (Long oral)

Estimating alpha-Rank from A Few Entries with Low Rank Matrix Completion

多智能体评估旨在根据用户策略的交互来评价他们之间的优劣。传统的方法,例如alpha-rank,通常通过两两对比的方式来实现。这在现实中是十分耗时的。在本文中,我们希望能够降低策略之间的比较次数并能准确估计最终排序的结果。我们的核心假设是相似智能体与其他智能体的优劣关系具有相似性。我们考虑两种情况,一种是完全已知真实的payoff矩阵,另一种是只能观察到带有噪声的payoff矩阵。我们发现在这两种情况下,我们都可以用O(nrlog n)(其中n是智能体个数,r是payoff矩阵的秩)次比较就可以预测出排序结果。我们设计了大量实验来验证算法的正确性。我们算法在十二个来自OpenSpiel的游戏玩家评估中,用少量对战次数就达到了与用完整payoff matrix 算法评估相似的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢